
تنسورفلو
تنسرفلو یک کتاب خانه یادگیری ماشین و یادگیری عمیق است که توسط گوگل منتشر شده است و گوگل برای این که کاربراش تجربه کاربری بهتری داشته باشند این لایبری رو جا های مختلفی استفاده کرده یکی ازا این مثال ها وقتی هست که شما شروع به جست و جو می کنید و گوگل به صورت خودکار نوشته شما رو کامل می کنه.
سه دسته از آدما از یادگیری ماشین استفاده می کنند ۱. محققین ۲. دانشمندان علوم داده ۳. برنامه نویس هابرای پاسخ گویی به نیاز این افراد تیم گوگل برین لایبرری تنسورفلو را اینجاد کرده تنسورفلو می تونه روی cpu ها و gpu های مختلف اجرا بشه و با زبان های مختلفی همچون c++ پایتون یا جاوا استفاده بشه. تنسورفلو از سرور ها بگیرید تا حتی روی موبایل ها می تونه اجرا بشه.
تاریخچه تنسورفلو
از زمانی که حجم اطلاعات زیاد شد یادگیری عمیق شروع کرد بر الگوریتم های یادگیری عمیق غلبه کنه و خب گوگل هم به این نتیجه رسید که می تونه با این شبکه های عصبی عمیق خدماتش ارتقاء بده و شروع کردن به ساخت فریم ورکی به اسم تنسورفلو که می تونست کمک کنه که توسعه دهنده ها و محققین همزمان روی مدل های هوش مصنوعی باهم کار کنند.
وقتی که پروژه به اندازه کافی توسعه پیدا کرد و مقیاس پذیری خوبی پیدا کرد در سال 2015 به صورت عمومی منتشر شد. البته تا سال 2017 هنوز ورژن پایدارش منتشر نشده بود.
ویژگی مهم تنسورفلو اینه که اپن سورس هست و مجوزش هم آپاچی هست پس راحت می تونید ازش استفاده کنید، ویرایشش کنید و توزیع خودتون منتشر کنید حتی می تونید ازش درآمد کسب کنید بدون اینکه نیاز باشه به گوگل پولی بدهید .
معماری تنسورفلو
معماری تنسورفلو سه قسمت داره که میشه ۱. پیش پردازش دیتا ها ۲. ساخت مدل ۳. تعلیم و تخمین مدل دلیل این نام گذاری به تنسورفلو اینه که به عنوان ورودی آرایه های چند بعدی ای دریافت می کنه که اسمشون tensor هست و بعد شما می تونید یک سری گراف هایی از عملیات ها بر روی دیتا های خود اجرا کنید که به صورت flowchart هست.
کجا اجرا میشه؟
برای استفاده از این لایبرری دو فاز وجود داره:
فاز توسعه: وقتی هست که مدل رو تعلیم می دید که این فاز معمولا روی لپ تاپ یا سیستمتون انجام میشه.
فاز اجرا: وقتی تعلیم تموم شد شما می تونید هرجایی از دسکتاپ بگیر تا سرور ها و حتی موبایل ها مدلتون رو ران کنید.
پس تعلیم و اجرا مدل می تونه روی ماشین های مختلفی انجام بشه.
علاوه بر استفاده از CPU ها شما می تونید روی GPU هم تنسورفلو رو اجرا کنید.
توی محاسبات ماتریکسی چون که یه عملگر یکسان روی تعداد زیادی از اطلاعات انجام می گیره، این نوع از محاسبات با ساختار GPU ها منطبقه این نکته رو اواخر سال 2010 محققین استفورد کشف کردند.
یک نکته دیگه اینکه این لایبرری با زبان C++ نوشته شده پس خیلی سریع هست البته می تونید با سایر زبان ها مثل پایتون ازش استفاده کنید.
یک ویژگی مهم تنسورفلو، تنسوربورد هست که به شما اجازه می ده مشاهده کنید تنسورفلو چکار داره می کنه.
اجزا تنسورفلو
تنسور
یک تنسور آرایه ای از ماتریکس های N بعدی هست که می تونند انوع اطلاعات رو نمایش بدند. هر مقداری در تنسور اطلاعاتی با شکل یکسانی (Shape) نگه می دارند.
تنسور ها می تونند ورودی یا خروجی یک محاسبه باشند.
گراف
در تنسورفلو همه عملیات ها داخل گراف انجام می شوند. هر گراف مجوعه ای از محاسبات هست که پیوسته انجام می شوند. هر محسابه ای با نام op node شناخته می شه که به هم دیگه وصل هستند.
حالا چرا گراف؟
- می تونه روی سیستم های مختلف اجرا بشه
- گراف می شه ذخیره کرد که بعدا استفاده کرد
- همه محاسبات در گراف با اتصال تنسور ها به هم اجرا می شه.
- به صورت خلاصه این که توی گراف ها هر یالی یک مقدار (تنسور) هست و هر گره یک عملگر( مثلا جمع) هست.
چرا تنسورفلو مشهوره؟
تنسورفلو بهترینه چونکه برای استفاده همه ساخته شده و تز api هایی استفاده میشه که بشه در مقیاس های مختلف از معماری های یادگیری عمیق همچون RNN, CNN استفاده کرد. چونکه بر اساس محاسبات گراف هست توانایی تجسم شبکه های عصبی داخل TensorBoard رو داره که خب برای دیباگ خیلی مفیده. و در کل اینکه تنسورفلو ساخته شده برای مقیاس پذيری در زمان استقرار.
یک خبر خوب اینکه بزرگترین کامیونیتی را در بین فریم ورک های مختلف یادگیری عمیق در گیت هاب داره.
چند تا از الگوریتم ها که توسط تنسورفلو پشتیبانی میشه چیه؟
- رگرسیون خیطی: tf.estimator.LinearRegressor
- طبقه بندی: tf.estimator.LinearClassifier
- طبقه بندی عمیق: tf.estimator.DNNClassifier
- Deep learning wipe and deep: tf.estimator.DNNLinearCombinedClassifier
- Booster tree regression: tf.estimator.BoostedTreesRegressor
- Boosted tree classification: tf.estimator.BoostedTreesClassifier
چند مثال ساده
- 12import numpy as np
- import tensorflow as tf
توی دو خط بالا لایبرری numpy و tensorflow رو وارد می کنیم.
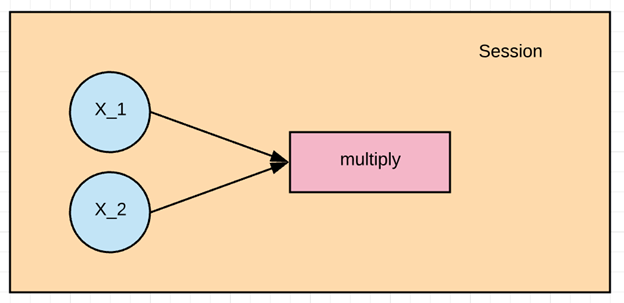
در این مثال می خواییم X_1 و X_2 را ضرب کنیم. اول باید گراف رو بسازیم و بعد یک session تنسورفلو ران کنیم که نتیجه رو محاسبه کنه.
بریم شروع کنیم
مرحله ۱: تعریف متغیر
اولین قدم باید نود های ورودی X_1 , X_2 را بسازیم. تو تنسورفلو باید مشخص کنیم چه نوع نودی قراره بسازیم که اینجا نوع placeholder رو انتخاب می کنیم.
placeholder:
این نوع در هر زمان که ما یک محاسبه انجام می دهیم یک مقدار جدید به تنسور اختصاص می دهد.
- X_1 = tf.placeholder(tf.float32, name = “X_1”)
- X_2 = tf.placeholder(tf.float32, name = “X_2”)
همونطور که می بینید به عنوان ورودی نوع این نود رو float و اسمش هم اسم متغییر وارد کردیم.
مرحله ۲: تعریف محاسبه
- 1multiply = tf.multiply(X_1, X_2, name = “multiply”)
با خط بالا داریم یک راس می سازیم که نقش عملگر عملگر ضرب رو داره
که ورودی اون راس هایی هست که میخواییم ضرب بشند و اسمش هم گذاشتیم multiply
خب الان اولین گرافمون رو ساختیم.
مرحله ۳: اجرا عملیات
برای اجرا عملیات باید یک جلسه یا session اجرا کنیم. با استفاده از tf.Session() این جلسه ایجاد می شه و وقتی از run استفاده کنیم اونو اجرا می کنه.
وقتی که ضرب رو قراره run کنیم باید به ورودی مقادیر تنسور های x1 و x2 رو بدهیم اینکار با تخصیص feed_dict انجام میشه. توی این مثال مقادیر 1 تا 3 به x1 و 4 تا 6 به x2 اختصاص پیدا کرده. و نتیجه رو چاپ کردیم.
- X_1 = tf.placeholder(tf.float32, name = “X_1”)
- X_2 = tf.placeholder(tf.float32, name = “X_2”)
- 1multiply = tf.multiply(X_1, X_2, name = “multiply”)
- with tf.Session() as session:
- result = session.run(multiply, feed_dict={X_1:[1,2,3], X_2:[4,5,6]})
- print(result)
- [ 4. 10. 18.]
راه های مختلف وارد کردن دیتا در تنسورفلو
خب یکی از اولین مراحل قبل از آموزش مدل وارد کردن دیتا هست. که دو حالت داره:
- وارد کردن اطلاعات به حافظه رم: یه راه ساده هست که اطلاعات وارد یک آرایه مموری می کنید مثلا یک خط کد به زبان پایتون می نویسید.
- استفاده از خط لوله دیتا تسورفلو: تنسورفلو یک سری api داره که کمک می کنه دیتا رو وارد کنید و یک سری عملیات روشون انجام بدید و سپس به الگوریتمتون بدید.این متد خیلی موثره مخصوصا وقتی که دیتاست خیلی بزرگه. برای مثال تصاویر عظیم هستند و در رم جا نمی شند. اینجا دیتا پایپ لاین عمل مدیریت حافظه رم شما رو به عهده می گیره.
سوالی که الان وجود داره اینه که از کدوم استفاده کنیم
اگه دیتا شما کمتر از ۱۰ گیگ هست که راحت می تونید از متد اول استفاده کنید مثلا یک لایبرری مشهور برای این کار pandas هست. در غیر این صورت مثلا اگه ۳۰ گیگ اطلاعات دارید و رمتون ۱۲ گیگ هست طبیعتا نمی تونید از این روش استفاده کنید و باید برید سراغ api پایپ لاین. پایپ لاین دیتا ها رو دسته دسته (batch) می کنه و هر دسته وارد پایپ لاین شده و برای یاد گرفتن مدل استفاده میشه. استفاده از پایپ لاین باعث میشه که بتونید از پردازش موازی استفادع کنید. یعنی تنسورفلو می تونه در چند cpu مختلف همزمان مدل رو آموزش بده.
خلاصه که اگه دیتاست شما کوچکه کامل داخل مموری رم واردش کنید مثلا با pandas در غیر این صورت یا اگه می خوایید از چند cpu استفاده کنید از پایپ لاین تنسورفلو استفاده کنید.
ایجاد خط لوله در تنسورفلو
مرحله ۱) ساخت دیتا
با لایبرری numpy دو تا عدد رندم می سازیم
- 123import numpy as np
- x_input = np.random.sample((1,2))
- print(x_input)
- 1[[0.8835775 0.23766977]]
مرحله ۲) ساخت placeholder
توی این مرحله یک placeholder به اسم X به صورت یک آرایه با دو عضو از نوع float می سازیم
- using a placeholder #
- x = tf.placeholder(tf.float32, shape=[1,2], name = ‘X’)
مرحله ۳: ساخت dataset
در این مرحله ما باید dataset رو تعریف کنیم که مقدار placeholder x داخلش قرار بدیم.
- 1tf.data.Dataset.from_tensor_slices
- 1dataset = tf.data.Dataset.from_tensor_slices(x)
مرحله ۴: ساخت پایپ لاین
در این مرحله ما باید پایپ لاین رو مقدار دهی اولیه کنیم که اولین قدم یک iterator می سازیم که بر روی دیتا ها جریان داشته باشه. با متد get_next مقدار بعدی رو می گیریم که در این مثال یک batch موجود است که فقط دو مقدار دارد.
- 12iterator = dataset.make_initializable_iterator()
- get_next = iterator.get_next()
مرحله ۵: اجرا محاسبه
در مرحله آخر یک سشن اجرا می کنیم که ورودی آن iterator و مقادیر ورودی هست که توسط numpy ساخته شده است. و برای هر کدوم مقدارش چاپ می کنیم.
- with tf.Session() as sess:
- # feed the placeholder with data
- sess.run(iterator.initializer, feed_dict={ x: x_input })
- print(sess.run(get_next))
- 1[0.8835775 0.23766978]
خلاصه
تنسورفلو مشهور ترین کتاب خونه یادگیری عمیق هست که با استفاده از اون می تونید از هر گونه ساختار یادگیری عمیق بهره ببرید. گوگل برین این پروژه را توسعه داده که فاصله بین تیم های تحقیقاتی و تیم های توسعه رو پر کنه و تقریبا گوگل در تمام پروژه هاش ازش استفاده می کنه. یکی از دلایل اصلی استفاده از تنسورفلو آسان بودن مقیاس پذیر شدن در زمان Deploy هست. تنسورفلو از سرور های قدرتمند تا گوشی های Android , IOS قابل استفاده هست.
تنسورفلو در یک session کار می کنه که هر جلسه به وسیله یک گراف با محاسبات مختلف تعریف شده است.
به عنوان یک مثال ساده در تنسورفلو ضرب به صورت زیر است
1.تعریف متغیر
- X_1 = tf.placeholder(tf.float32, name = “X_1”)
- X_2 = tf.placeholder(tf.float32, name = “X_2”)
۲. تعریف محاسبه
- 1multiply = tf.multiply(X_1, X_2, name = “multiply”)
۳. اجرای عملیات
- with tf.Session() as session:
- result = session.run(multiply, feed_dict={X_1:[1,2,3], X_2:[4,5,6]})
- print(result)
یک عمل رایج در تنسورفلو ایجاد پایپ لاین هست برای load دیتا در حافظه رم که با مراحل زیر انجام می شه:
1. ساخت دیتا ها
- import numpy as np
- x_input = np.random.sample((1,2))
- print(x_input)
۲. ساخت place holder
- 1x = tf.placeholder(tf.float32, shape=[1,2], name = ‘X’)
۳. تعریف متد دیتاست
- 1dataset = tf.data.Dataset.from_tensor_slices(x)
۴. ساخت خط لوله
- 1iterator = dataset.make_initializable_iterator() get_next = iteraror.get_next()
۵. اجرا برنامه
- with tf.Session() as sess:
- sess.run(iterator.initializer, feed_dict={ x: x_input })
- print(sess.run(get_next))







