
مقدمه
این آموزش نحوه نصب Ollama را برای اجرای مدل های زبان روی سرور با اوبونتو یا دبیان توضیح می دهد. همچنین نحوه راه اندازی یک رابط چت با Open WebUI و نحوه استفاده از یک مدل زبان سفارشی را نشان می دهد.
پیش نیازها
- یک سرور با اوبونتو/دبیان
- شما نیاز به دسترسی به کاربر ریشه یا کاربری با مجوز sudo دارید.
- قبل از شروع، باید برخی از تنظیمات اولیه، از جمله فایروال را تکمیل کنید.
مرحله 1 – اوللاما را نصب کنید
مرحله زیر نحوه نصب Ollama را به صورت دستی توضیح می دهد. برای شروع سریع، می توانید از اسکریپت نصب استفاده کنید و با “مرحله 2 – نصب Ollama WebUI” ادامه دهید.
برای نصب Ollama خودتان، این مراحل را دنبال کنید:
اگر سرور شما دارای پردازنده گرافیکی Nvidia است، مطمئن شوید که درایورهای CUDA نصب شده باشند
nvidia-smi
اگر درایورهای CUDA نصب نشدهاند، همین الان این کار را انجام دهید. در این پیکربندی، می توانید سیستم عامل خود را انتخاب کنید و نوع نصب کننده را انتخاب کنید تا دستوراتی را که برای اجرا با تنظیمات خود نیاز دارید مشاهده کنید.
sudo apt update
sudo apt install -y nvidia-kernel-open-545
sudo apt install -y cuda-drivers-545
باینری Ollama را دانلود کنید و یک کاربر Ollama ایجاد کنید
sudo curl -L https://ollama.ai/download/ollama-linux-amd64 -o /usr/bin/ollama
sudo chmod +x /usr/bin/ollama
sudo useradd -r -s /bin/false -m -d /usr/share/ollama ollamaیک فایل سرویس ایجاد کنید. بهطور پیشفرض، میتوانید از طریق پورت 11434 127.0.0.1 به Ollama API دسترسی داشته باشید. این بدان معناست که API فقط برای لوکال هاست در دسترس است.
اگر نیاز به دسترسی خارجی به Ollama دارید، می توانید Environment را حذف کنید و یک آدرس IP برای دسترسی به Ollama API تنظیم کنید. 0.0.0.0 به شما امکان می دهد از طریق IP عمومی سرور به API دسترسی داشته باشید. اگر از Environment استفاده میکنید، مطمئن شوید که فایروال سرور شما اجازه دسترسی به پورتی را که تنظیم کردهاید، در اینجا 11434 میدهد.اگر فقط یک سرور دارید، نیازی به تغییر دستور زیر ندارید.
کل محتوای بلوک کد زیر را کپی و پیست کنید. این فایل جدید /etc/systemd/system/ollama.service را ایجاد می کند و محتوای بین EOF را به فایل جدید اضافه می کند.
sudo bash -c 'cat <<'EOF' >> /etc/systemd/system/ollama.service
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
#Environment="OLLAMA_HOST=0.0.0.0:11434"
[Install]
WantedBy=default.target
EOF'
دیمون systemd را دوباره بارگیری کنید و سرویس Ollama را فعال کنید
sudo systemctl daemon-reload
sudo systemctl enable ollama
sudo systemctl start ollamaاز systemctl status olama برای بررسی وضعیت استفاده کنید. اگر Olama فعال و در حال اجرا نیست، مطمئن شوید که systemctl start olama را اجرا کرده اید.
در ترمینال، اکنون میتوانید مدلهای زبان را شروع کنید و سؤال بپرسید. مثلا:
ollama run llama2
مرحله بعدی نحوه نصب یک رابط کاربری وب را توضیح می دهد تا بتوانید از طریق یک مرورگر وب سوالات خود را در یک رابط کاربری زیبا بپرسید.
مرحله 2 – Open WebUI را نصب کنید
در اسناد Olama در GitHub، می توانید لیستی از ادغام های مختلف وب و ترمینال را بیابید. این مثال نحوه نصب Open WebUI را توضیح می دهد.
میتوانید Open WebUI را روی همان سروری که Ollama نصب کردهاید، یا Ollama و Open WebUI را روی دو سرور جداگانه نصب کنید. اگر Open WebUI را روی یک سرور جداگانه نصب می کنید، مطمئن شوید که Ollama API در معرض شبکه شما قرار دارد. برای بررسی مجدد، /etc/systemd/system/olama.service را در سروری که Ollama نصب کرده است مشاهده کنید و مقدار OLLAMA_HOST را تأیید کنید.
مراحل زیر نحوه نصب رابط کاربری را توضیح می دهد:
- به صورت دستی
- با داکر
Open WebUI را به صورت دستی نصب کنید
npm و pip را نصب کنید، مخزن WebUI را کلون کنید و یک کپی از فایل محیط مثال ایجاد کنید:
sudo apt update && sudo apt install npm python3-pip git -y
git clone https://github.com/ollama-webui/ollama-webui.git
cd ollama-webui
cp -RPp example.env .envدر env. آدرس برای اتصال به Ollama API به طور پیش فرض روی localhost:11434 تنظیم شده است. اگر Ollama API را روی همان سرور Open WebUI خود نصب کردهاید، میتوانید این تنظیمات را همانطور که هست رها کنید. اگر Open WebUI را روی سرور جداگانه ای غیر از Ollama API نصب کرده اید، env. را ویرایش کرده و آدرس سروری را که Olama نصب کرده است، جایگزین مقدار پیش فرض کنید.
وابستگی های لیست شده در package.json را نصب کنید و اسکریپت با نام build را اجرا کنید:
npm i && npm run build
بسته های پایتون مورد نیاز را نصب کنید:
cd backend
sudo pip install -r requirements.txt -Uرابط کاربری وب را با olama-webui/backend/start.sh شروع کنید.
sh start.shدر start.sh، پورت روی 8080 تنظیم شده است. به این معنی که می توانید به Open WebUI در http://<ip-adress>:8080 دسترسی داشته باشید. اگر فایروال فعالی روی سرور خود دارید، قبل از اینکه بتوانید به رابط کاربری چت دسترسی پیدا کنید، باید به پورت اجازه دهید. برای این کار، اکنون می توانید به «مرحله 3 – اجازه دادن به پورت به وب UI» بروید. اگر فایروال ندارید که توصیه نمی شود، اکنون می توانید به «مرحله 4 – افزودن مدل ها» بروید.
Open WebUI با Docker را نصب کنید
برای این مرحله باید داکر را نصب کنید. اگر هنوز Docker را نصب نکرده اید، اکنون می توانید با استفاده از این آموزش این کار را انجام دهید.
همانطور که قبلاً ذکر شد، می توانید انتخاب کنید که Open WebUI را روی همان سروری که Ollama نصب کرده است یا Ollama و Open WebUI را روی دو سرور جداگانه نصب کنید.
Open WebUI را روی همان سرور اوللاما نصب کنید
sudo docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
Open WebUI را روی سروری متفاوت از اوللاما نصب کنید
sudo docker run -d -p 3000:8080 -e OLLAMA_API_BASE_URL=http://<ip-adress>:11434/api -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
در دستور Docker بالا، پورت روی 3000 تنظیم شده است. این به این معنی است که می توانید به Open WebUI در http://<ip-adress>:3000 دسترسی داشته باشید. اگر فایروال فعالی روی سرور خود دارید، قبل از اینکه بتوانید به رابط کاربری چت دسترسی پیدا کنید، باید به پورت اجازه دهید. این در مرحله بعد توضیح داده شده است.
مرحله 3 – به پورت به رابط کاربری وب اجازه دهید
اگر فایروال دارید، مطمئن شوید که اجازه دسترسی به درگاه Open WebUI را می دهد. اگر آن را به صورت دستی نصب کرده اید، باید پورت 8080 TCP را مجاز کنید. اگر آن را با Docker نصب کرده اید، باید به پورت 3000 TCP اجازه دهید.
برای بررسی مجدد، می توانید از netstat استفاده کنید و ببینید که کدام پورت ها استفاده می شوند.
holu@<your-server>:~$ netstat -tulpn | grep LISTEN
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 127.0.0.1:11434 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:8080 0.0.0.0:* LISTENچندین ابزار مختلف فایروال وجود دارد. این آموزش ابزار پیکربندی فایروال پیش فرض برای Ubuntu ufw را پوشش می دهد. اگر از فایروال دیگری استفاده می کنید، مطمئن شوید که به ترافیک ورودی به پورت 8080 یا 3000 TCP اجازه می دهد.
مدیریت قوانین فایروال ufw:
- تنظیمات فعلی فایروال را مشاهده کنید
برای بررسی اینکه آیا فایروال ufw فعال است و آیا قبلاً قوانینی دارید، می توانید از موارد زیر استفاده کنید:
sudo ufw status
- پورت 8080 یا 3000 TCP را مجاز کنید
اگر فایروال فعال است، این دستور را اجرا کنید تا ترافیک ورودی به پورت 8080 یا 3000 TCP اجازه داده شود:
sudo ufw allow proto tcp to any port 8080
- مشاهده تنظیمات جدید فایروال
اکنون باید قوانین جدید اضافه شود. برای بررسی، از:
sudo ufw status
مرحله 4 – مدل ها را اضافه کنید
پس از دسترسی به رابط کاربری وب، باید اولین حساب کاربری را ایجاد کنید. این کاربر دارای حقوق مدیریت خواهد بود. برای شروع اولین چت خود، باید مدلی را انتخاب کنید. می توانید لیستی از مدل ها را در وب سایت رسمی اوللاما مرور کنید. در این مثال “llama2” را اضافه می کنیم.
در گوشه بالا سمت راست، نماد تنظیمات را انتخاب کنید
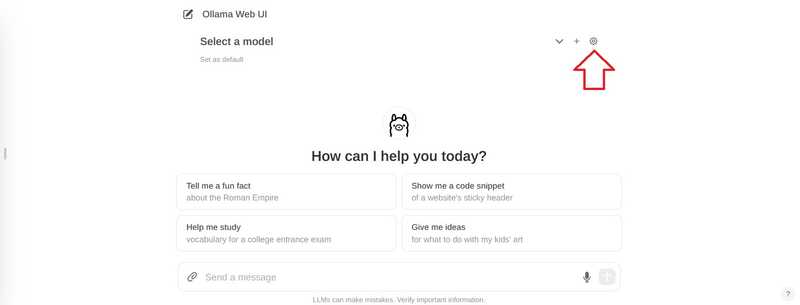
به “مدل ها” بروید، یک مدل را وارد کنید و دکمه دانلود را انتخاب کنید.
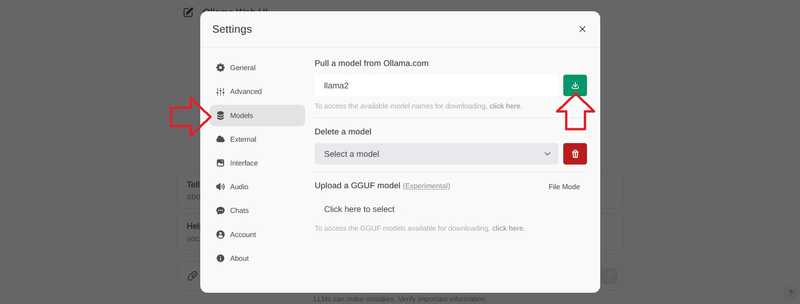
صبر کنید تا این پیام ظاهر شود:
Model 'llama2' has been successfully downloaded.
برای بازگشت به چت تنظیمات را ببندید.
در چت، روی “انتخاب مدل” در بالا کلیک کنید و مدل خود را اضافه کنید.
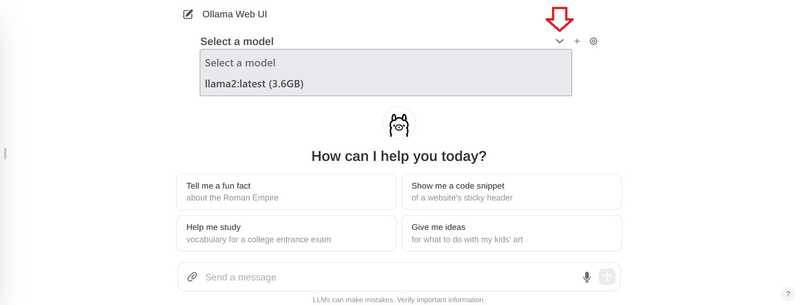
اگر می خواهید چندین مدل اضافه کنید، می توانید از علامت + در بالا استفاده کنید.
هنگامی که مدل هایی را که می خواهید استفاده کنید اضافه کردید، می توانید شروع به پرسیدن سوالات خود کنید. اگر چندین مدل اضافه کرده اید، می توانید بین پاسخ ها جابجا شوید.

مرحله 5 – مدل خود را اضافه کنید
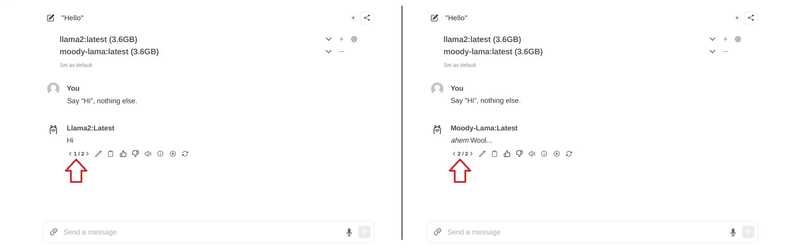
اگر میخواهید مدلهای جدیدی را از طریق رابط کاربری اضافه کنید، میتوانید این کار را از طریق http://<ip-adress>:8080/modelfiles/create/ انجام دهید. در صورت نیاز 8080 را با 3000 جایگزین کنید.
موارد زیر بر روی افزودن یک مدل جدید از طریق ترمینال تمرکز خواهند کرد. ابتدا باید به سروری که olama را نصب کرده است وصل شوید. از لیست olama برای لیست کردن مدل هایی که تاکنون در دسترس هستند استفاده کنید.
- یک فایل مدل ایجاد کنید
میتوانید الزامات یک فایل مدل را در اسناد Olama در GitHub بیابید. در خط اول فایل مدل FROM <model> می توانید مشخص کنید که از چه مدلی می خواهید استفاده کنید. در این مثال، مدل موجود llama2 را اصلاح خواهیم کرد. اگر می خواهید یک مدل کاملاً جدید اضافه کنید، باید مسیر فایل مدل را مشخص کنید (به عنوان مثال FROM ./my-model.gguf).
nano new-model
این محتوا را ذخیره کنید:
FROM llama2
# The higher the number, the more creative are the answers
PARAMETER temperature 1
# If set to "0", the model will not consider any previous context or conversation history when generating responses. Each input is treated independently.
# If you set a high number such as "4096", the model will consider previous context or conversation history when generating responses. "4096" is the number of tokens that will be considered.
PARAMETER num_ctx 4096
# Set what "personality" the chat assistant should have in the responses. You can set "who" the chat assistant should respond as and in which style.
SYSTEM You are a moody lama that only talks about its own fluffy wool.یک مدل از فایل مدل ایجاد کنید
ollama create moody-lama -f ./new-model
- بررسی کنید که آیا مدل جدید موجود است یا خیر
از دستور olama برای لیست کردن همه مدل ها استفاده کنید. moody-lama نیز باید ذکر شود.
ollama list
- از مدل خود در WebUI استفاده کنید
وقتی به رابط کاربری وب باز میگردید، مدل اکنون باید در لیست انتخاب مدل نیز باشد. اگر هنوز نشان داده نشده است، ممکن است نیاز داشته باشید که بهسرعت بازخوانی کنید.
نتیجه
در این آموزش، شما یاد گرفتید که چگونه یک چت هوش مصنوعی را روی سرور خود میزبانی کنید و چگونه مدل های خود را اضافه کنید.









