
مقدمه
روشهای سنتی پردازش و دریافت دادهها (مانند پردازش دستهای و نظرسنجی) در زمینه ریزسرویسهای مورد استفاده در برنامههای مدرن ناکارآمد هستند. این روشها بر روی تکههای انبوه داده کار میکنند، که نتیجه نهایی پردازش آنها را به تاخیر میاندازد و مقدار قابل توجهی از دادهها را مجبور میکند تا قبل از آن انباشته شوند. آنها پیچیدگی اضافی لازم برای همگام سازی کارگران را معرفی می کنند و به طور بالقوه برخی از آنها را علیرغم استفاده از منابع، کم استفاده می کنند. در مقابل، از آنجایی که رایانش ابری مقیاسپذیری سریعی را برای منابع مستقر ارائه میدهد، دادههای دریافتی را میتوان با تفویض موازی به چندین کارگر در زمان واقعی پردازش کرد.
جریان رویداد رویکرد جمعآوری انعطافپذیر و واگذاری رویدادهای دریافتی برای پردازش با حفظ جریان مداوم دادهها بین سیستمهای مختلف است. زمانبندی دادههای دریافتی برای پردازش فوراً حداکثر استفاده از منابع و پاسخگویی در زمان واقعی را تضمین میکند. پخش جریانی رویداد، تولیدکنندگان را از مصرفکنندگان جدا میکند و به شما امکان میدهد بسته به بار فعلی، تعداد نامتناسبی از هر کدام داشته باشید. این امکان واکنش های آنی به شرایط پویا در دنیای واقعی را فراهم می کند.
چنین پاسخگویی می تواند به ویژه در زمینه هایی مانند تجارت مالی، نظارت بر پرداخت ها یا مشاهده ترافیک مهم باشد. به عنوان مثال، Uber از جریان رویداد برای اتصال صدها میکروسرویس استفاده می کند، داده های رویداد را از برنامه های سوار به راننده در زمان واقعی ارسال می کند و آنها را برای تجزیه و تحلیل بعدی بایگانی می کند.
با پخش رویداد، بهجای اینکه کارگر بهطور سنتی در یک بازه زمانی منظم منتظر دستهای از دادهها باشد، کارگزار رویداد میتواند به محض وقوع رویداد، مصرفکننده (معمولاً یک میکروسرویس) را مطلع کند و دادههای رویداد را در اختیار او قرار دهد. کارگزار رویداد از مسیریابی، دریافت و انتقال رویدادها مراقبت می کند. همچنین در صورت عدم موفقیت یا رد کردن یک کارگر از پردازش یک رویداد، تحمل خطا را فراهم می کند.
در این مقاله مفهومی، رویکرد جریان رویداد و مزایای آن را بررسی خواهیم کرد. همچنین آپاچی کافکا، یک بروکر رویداد منبع باز را معرفی می کنیم و نقش آن را در این رویکرد بررسی می کنیم.
معماری جریان رویداد
جریان رویداد در هسته خود، اجرای الگوی معماری میخانه/فرعی است. به طور کلی، الگوی pub/sub شامل:
- موضوعاتی که پیام ها (شامل هر داده ای که می خواهید ارتباط برقرار کنید) به آنها خطاب می شود.
- ناشران که پیام تولید می کنند
- مشترکینی که پیام ها را دریافت می کنند و به آنها عمل می کنند
- کارگزاری پیام که پیامهای ناشران را میپذیرد و به کارآمدترین روش در اختیار مشترکین قرار میدهد
یک موضوع شبیه به مقوله ای است که یک پیام به آن مرتبط است. موضوعات به طور بادوام توالی پیام ها را ذخیره می کنند و تضمین می کنند که پیام های جدید همیشه به انتهای دنباله اضافه می شوند. هنگامی که یک پیام به موضوع اضافه شد، نمی توان آن را بعداً تغییر داد.
با پخش رویداد، فرض مشابه است، هرچند تخصصی تر:
- رویدادها و ابرداده های مرتبط با هم به عنوان پیام ارسال می شوند
- رویدادها در یک موضوع معمولاً بر اساس زمان ورود مرتب می شوند
- مشترکین (که مصرف کنندگان نیز نامیده می شوند) می توانند رویدادها را از هر نقطه ای از موضوع تا لحظه فعلی پخش کنند.
- برخلاف میخانه/زیر واقعی، رویدادهای یک موضوع را می توان برای مدت زمان مشخصی نگه داشت یا به طور نامحدود (به عنوان بایگانی) نگهداری کرد.
جریان رویداد محدودیتی ایجاد نمی کند یا فرضیاتی در مورد ماهیت یک رویداد ایجاد نمی کند. تا آنجا که به کارگزار اصلی مربوط می شود، به این معنی است که یک تولیدکننده به او اطلاع داده است که چیزی رخ داده است. آنچه در واقع اتفاق افتاده است به شما بستگی دارد که پیاده سازی خود را تعریف کرده و به آن معنا بدهید. به همین دلیل، از دیدگاه کارگزار، رویدادها به جای یکدیگر پیام یا رکورد نامیده می شوند.
برای نشان دادن، در اینجا یک نمودار دقیق از معماری جریان رویداد کافکا از مستندات Confluent آورده شده است:
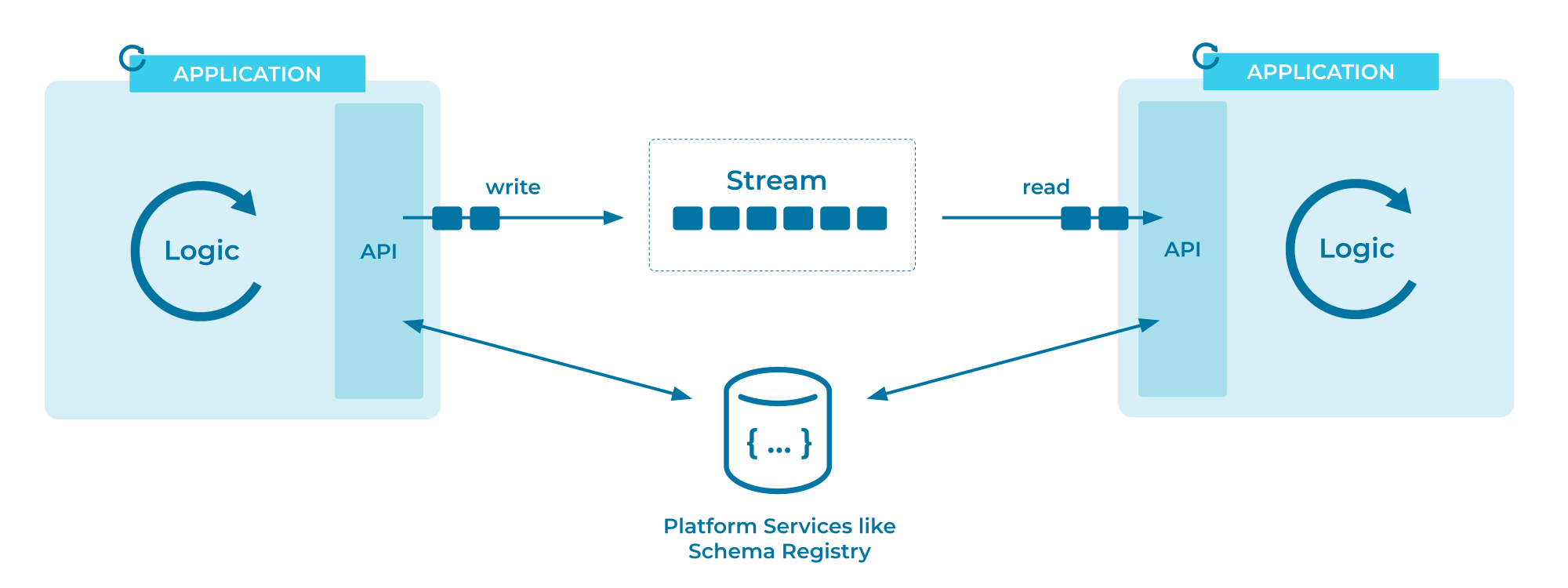
دو مدل برای اینکه مصرف کنندگان چگونه می توانند داده ها را از یک کارگزار دریافت کنند وجود دارد: فشار دادن و کشیدن. Pushing به کارگزار رویداد اشاره دارد که فرآیند ارسال داده ها را به یک مصرف کننده در دسترس اولیه می کند، در حالی که کشش به این معنی است که مصرف کننده رکوردهای بعدی موجود را از کارگزار درخواست می کند. این تفاوت بی ضرر به نظر می رسد، اما کشیدن در عمل ترجیح داده می شود.
یکی از دلایل اصلی عدم استفاده گسترده از فشار دادن این است که کارگزار نمی تواند مطمئن باشد که مصرف کننده واقعاً می تواند در مورد رویداد عمل کند. بنابراین، ممکن است در نهایت رویداد را چندین بار بیهوده ارسال کند در حالی که همچنان نیاز به ذخیره آن در موضوع وجود دارد. کارگزار همچنین باید رویدادهای دستهای را برای بازدهی بالاتر در نظر بگیرد، که برخلاف ایده پخش هر چه سریعتر آنهاست.
اینکه مصرف کننده داده ها را زمانی که آماده پردازش است بکشد، ترافیک غیرضروری شبکه را کاهش می دهد و امکان اطمینان بیشتر را فراهم می کند. این تضمین می کند که فقط زمانی داده را دریافت می کند که آماده پردازش باشد. مدت زمان پردازش بستگی به منطق تجاری دارد و بر برنامه ریزی تعداد کارگران تأثیر می گذارد. در هر دو مورد، کارگزار باید به خاطر داشته باشد که مصرف کننده کدام رویدادها را تصدیق کرده است.
اکنون می دانید که جریان رویداد چیست و بر چه معماری مبتنی است. اکنون با مزایای این رویکرد پویا آشنا خواهید شد.
مزایای پخش جریانی رویداد
مزایای اصلی پخش رویداد عبارتند از:
- ثبات: کارگزار رویداد تضمین می کند که رویدادها به درستی برای همه مصرف کنندگان علاقه مند ارسال می شوند.
- تحمل خطا: اگر یک مصرف کننده نتواند رویدادی را بپذیرد، می توان آن را در جای دیگری تغییر مسیر داد تا اطمینان حاصل شود که هیچ رویدادی پردازش نشده باقی نمی ماند.
- قابلیت استفاده مجدد: رویدادهای ذخیره شده در یک موضوع تغییر ناپذیر هستند. آنها را می توان به طور کامل یا از یک نقطه خاص در زمان پخش کرد و به شما امکان می دهد در صورت تغییر منطق تجاری، رویدادها را دوباره پردازش کنید.
- مقیاس پذیری: تولیدکنندگان و مصرف کنندگان موجودیت های جداگانه ای هستند و مجبور نیستند منتظر یکدیگر باشند، به این معنی که بسته به تقاضا می توان آنها را به صورت پویا افزایش یا کاهش داد.
- سهولت استفاده: کارگزار رویداد مسیریابی و ذخیرهسازی رویداد را مدیریت میکند، منطق پیچیده را انتزاع میکند و به شما امکان میدهد روی خود دادهها تمرکز کنید.
هر رویداد باید فقط حاوی جزئیات لازم در مورد وقوع باشد. بروکرهای رویداد عموماً بسیار کارآمد هستند، و اگرچه توصیه میشود که رویدادها پس از وارد شدن به یک موضوع منقضی نشود، نباید به عنوان یک پایگاه داده سنتی در نظر گرفته شوند.
به عنوان مثال، خوب است نشان دهیم که تعداد بازدیدهای یک مقاله تغییر کرده است، اما نیازی به ذخیره کل مقاله و ابرداده مربوط به آن به همراه این واقعیت نیست. در عوض، رویداد میتواند حاوی ارجاع به شناسه مقاله در یک پایگاه داده خارجی باشد. به این ترتیب، تاریخ همچنان بدون درج اطلاعات غیر ضروری و آلوده کردن موضوع قابل پیگیری است.
اکنون در مورد آپاچی کافکا و سایر کارگزاران رویداد محبوب، نحوه مقایسه آنها و نحوه ورود آنها به اکوسیستم پخش رویدادها خواهید آموخت.
نقش آپاچی کافکا
آپاچی کافکا یک کارگزار رویداد منبع باز است که به زبان جاوا نوشته شده و توسط بنیاد نرم افزار آپاچی نگهداری می شود. این شامل سرورهای توزیع شده و کلاینت هایی است که با استفاده از پروتکل شبکه TCP سفارشی برای حداکثر کارایی ارتباط برقرار می کنند. کافکا بسیار قابل اعتماد و مقیاس پذیر است و می تواند بر روی ماشین های مجازی، سخت افزارهای فلزی خالی، کانتینرها و سایر محیط های ابری اجرا شود.
برای قابلیت اطمینان، کافکا به عنوان یک خوشه شامل یک یا چند سرور مستقر شده است. این خوشه می تواند چندین منطقه ابری و مراکز داده را پوشش دهد. خوشههای کافکا تحملپذیر خطا هستند، به این معنی که در صورت خرابی یا قطع اتصال سرور، باقیماندهها مجدداً گروهبندی میشوند تا از دسترسی بالا به عملیاتها بدون تأثیر خارجی و از دست دادن داده اطمینان حاصل کنند.
برای حداکثر کارایی، همه سرورهای کافکا نقش یکسانی ندارند. برخی از سرورها با هم گروه می شوند و به عنوان واسطه عمل می کنند و لایه ذخیره سازی را برای نگهداری داده ها تشکیل می دهند. بقیه میتوانند با سیستمهای موجود شما ادغام شوند و دادهها را بهعنوان جریان رویداد با استفاده از Kafka Connect، ابزاری برای پخش مطمئن دادهها از سیستمهای موجود (مانند پایگاههای داده رابطهای) به کافکا، جذب کنند.
کافکا تولیدکنندگان و مصرف کنندگان را مشتریان خود می داند. همانطور که قبلاً توضیح داده شد، تولیدکنندگان رویدادها را برای یک کارگزار کافکا می نویسند که آنها را برای مصرف کنندگان علاقه مند ارسال می کند. در پیکربندی پیشفرض، کافکا تضمین میکند که یک رویداد در نهایت تنها یک بار توسط یکی از مصرفکنندگان پردازش میشود.
در کافکا موضوعات تقسیم بندی می شوند. این به این معنی است که یک موضوع در بخشهایی در کارگزاران مختلف کافکا پخش میشود که مقیاسپذیری را تضمین میکند. کافکا همچنین تضمین می کند که رویدادهای ذخیره شده در ترکیب خاصی از موضوعات و پارتیشن های آنها همیشه می توانند به همان ترتیبی که نوشته شده اند خوانده شوند.
توجه داشته باشید که صرف پارتیشن بندی یک موضوع، افزونگی را تضمین نمی کند، که تنها از طریق تکرار در مناطق مختلف و مراکز داده قابل دستیابی است. معمول است که حداقل 3 کپی از یک خوشه در یک محیط تولید داشته باشید، به این معنی که سه ترکیب موضوع-پارتیشن همیشه در دسترس است.
ادغام کافکا
همانطور که گفته شد، داده های موجود در سیستم های موجود را می توان با استفاده از Kafka Connect وارد و صادر کرد. برای وارد کردن کل پایگاههای داده، گزارشها یا معیارها از سرورهای شما در موضوعاتی با تأخیر کم مناسب است. Kafka Connect کانکتورهایی برای سیستم های داده مختلف ارائه می دهد که به شما امکان می دهد داده ها را به روشی استاندارد مدیریت کنید. یکی دیگر از مزایای استفاده از کانکتورها به جای استفاده از راه حل های خود این است که Connect به طور پیش فرض مقیاس پذیر است (چند کارگر می توانند با هم گروه شوند) و به طور خودکار پیشرفت را ردیابی می کند.
برای برقراری ارتباط با کافکا از طریق برنامه های خود، تعداد زیادی از مشتریان در دسترس است. بسیاری از زبان های برنامه نویسی مانند جاوا، اسکالا، پایتون، دات نت، سی پلاس پلاس، گو و غیره پشتیبانی می شوند. یک کتابخانه مشتری سطح بالا به نام Kafka Streams نیز برای جاوا و اسکالا موجود است. این کتابخانه کارهای درونی را انتزاعی می کند و به شما امکان می دهد به راحتی به یک کارگزار کافکا متصل شوید و شروع به دریافت رویدادهای پخش شده کنید.
نتیجه
این مقاله پارادایمهای رویکرد جریان رویداد مدرن برای پردازش دادهها و رویدادها و مزایای آن را نسبت به فرآیندهای دستهبندی دادههای سنتی پوشش میدهد. شما همچنین در مورد آپاچی کافکا به عنوان یک واسطه رویداد و اکوسیستم مشتری آن اطلاعات کسب کرده اید.









