
مقدمه
تصور کنید که بتوانید با داده های بدون ساختار خود مکالمه کنید و اطلاعات ارزشمند را به راحتی استخراج کنید. در چشمانداز مبتنی بر دادههای امروزی، استخراج بینشهای معنادار از اسناد بدون ساختار همچنان یک چالش است و مانع از تصمیمگیری و نوآوری میشود. در این آموزش، با جاسازیها آشنا میشویم، با استفاده از جستجوی باز آمازون بهعنوان یک پایگاهداده برداری کاوش میکنیم و چارچوب Langchain را با مدلهای زبان بزرگ (LLMs) برای ساختن یک وبسایت با یک ربات چت NLP تعبیهشده یکپارچه میکنیم. ما به اصول LLM می پردازیم تا با کمک یک مدل زبان بزرگ منبع باز، بینش های معناداری را از یک سند بدون ساختار استخراج کنیم. در پایان این آموزش، شما درک جامعی از چگونگی به دست آوردن بینش معنادار از اسناد بدون ساختار و استفاده از مهارتها برای کشف و نوآوری با راهحلهای مبتنی بر هوش مصنوعی Full-Stack مشابه خواهید داشت.
پیش نیازها
- شما باید یک حساب AWS فعال داشته باشید. اگر ندارید، می توانید در وب سایت AWS ثبت نام کنید.
- اطمینان حاصل کنید که رابط خط فرمان AWS (CLI) را روی دستگاه محلی خود نصب کرده اید، و باید به درستی با اعتبارنامه های لازم و منطقه پیش فرض پیکربندی شده باشد. با استفاده از دستور aws configure می توانید آن را پیکربندی کنید.
- Docker Engine را دانلود و نصب کنید. دستورالعمل های نصب را برای سیستم عامل خاص خود دنبال کنید.
قرار است چه چیزی بسازیم؟
در این مثال، ما می خواهیم مشکلی را که بسیاری از شرکت ها با آن مواجه هستند، تقلید کنیم. بسیاری از دادههای امروزی ساختاری ندارند، بلکه ساختاری ندارند و به شکل رونوشتهای صوتی و تصویری، اسناد PDF و Word، کتابچههای راهنما، یادداشتهای اسکنشده، رونوشتهای رسانههای اجتماعی و غیره هستند. ما از مدل Flan-T5 XXL به عنوان LLM استفاده خواهیم کرد. این مدل می تواند خلاصه و پاسخ پرسش و پاسخ را از متون بدون ساختار تولید کند. تصویر زیر معماری بلوک های مختلف ساختمان را نشان می دهد.

بیایید با اصول شروع کنیم
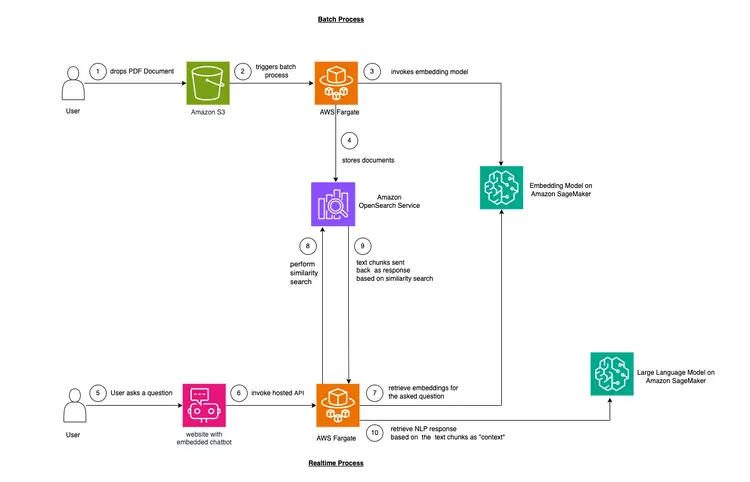
ما از تکنیکی به نام یادگیری درون متنی برای تزریق دامنه یا استفاده از “Context” خاص موردی به LLM خود استفاده خواهیم کرد. در این مورد، ما یک کتابچه راهنمای PDF بدون ساختار از یک خودرو داریم که میخواهیم آن را به عنوان «Context» برای LLM اضافه کنیم و میخواهیم LLM به سؤالات مربوط به این راهنما پاسخ دهد. به همین سادگی! هدف ما این است که با ایجاد یک API بیدرنگ که سوالات را دریافت میکند، آنها را به باطن ما ارسال میکند و از طریق یک ربات چت منبع باز تعبیهشده در وبسایت قابل دسترسی است، قدمی فراتر بگذاریم. این آموزش ما را قادر می سازد تا کل تجربه کاربر را بسازیم و بینش هایی را در مورد مفاهیم و ابزارهای مختلف در طول فرآیند به دست آوریم.
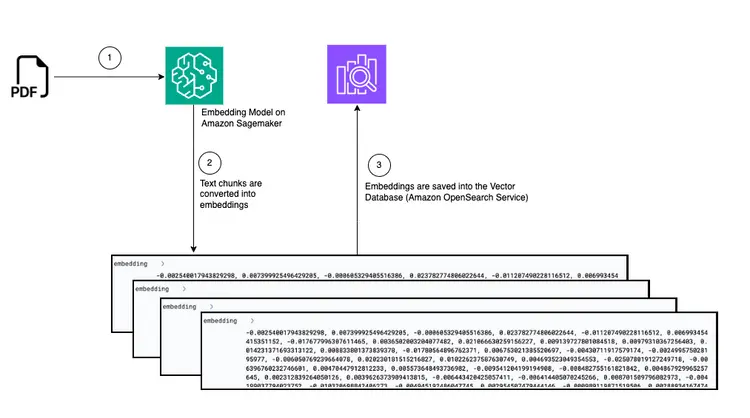
- اولین قدم برای ارائه یادگیری درون متنی، جذب سند PDF و تبدیل آن به تکه های متنی، تولید نمایش های برداری از این تکه های متنی به نام “جاسازی ها” و در نهایت ذخیره این جاسازی ها در یک پایگاه داده برداری است.
- پایگاههای داده برداری ما را قادر میسازد تا «جستجوی شباهت» را در برابر جاسازیهای متنی که در آن ذخیره میشوند، انجام دهیم.
- Amazon SageMaker JumpStart قالبهای راهحل اجرایی با یک کلیک را برای راهاندازی زیرساخت برای مدلهای منبع باز و از پیش آموزش دیده ارائه میکند. ما از Amazon SageMaker JumpStart برای استقرار مدل Embedding و مدل Large Language استفاده خواهیم کرد.
- آمازون OpenSearch یک موتور جستجو و تجزیه و تحلیل است که می تواند نزدیکترین همسایگان نقاط را در یک فضای برداری جستجو کند و آن را به عنوان یک پایگاه داده برداری مناسب می کند.
نمودار: تبدیل از PDF به جاسازی در پایگاه داده برداری

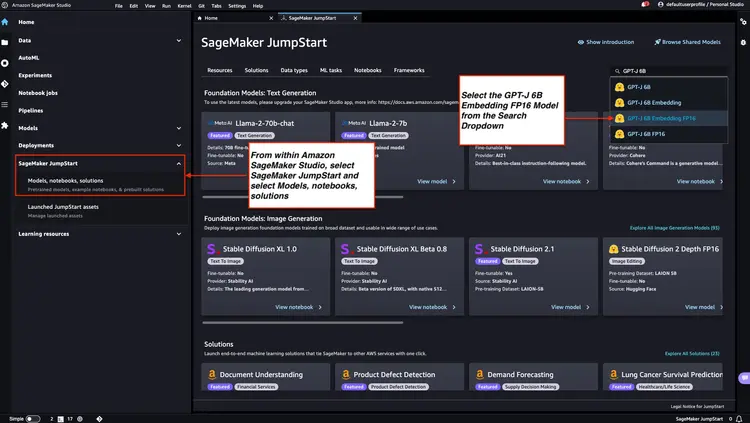
مرحله 1 - استقرار مدل جاسازی GPT-J 6B FP16 با Amazon SageMaker JumpStart
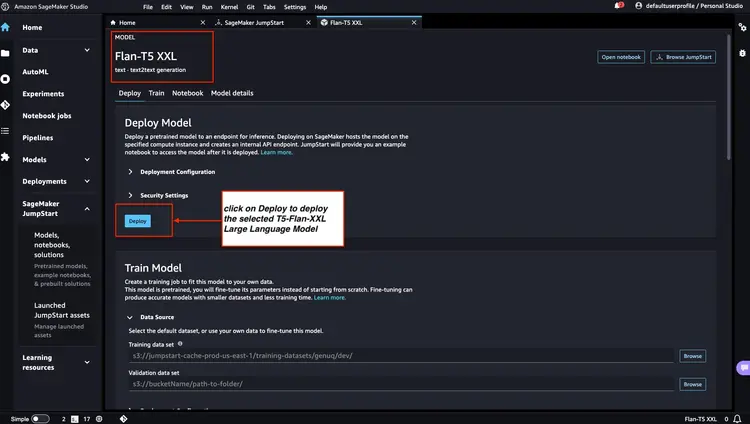
مراحل ذکر شده در Amazon SageMaker Documentation را دنبال کنید – بخش JumpStart را برای راه اندازی گره Amazon SageMaker JumpStart از منوی اصلی استودیوی Amazon SageMaker باز کرده و از آن استفاده کنید. گزینه Models, notebooks, solutions را انتخاب کنید و مدل جاسازی GPT-J 6B Embedding FP16 را مطابق تصویر زیر انتخاب کنید. سپس، روی ‘Deploy’ کلیک کنید و Amazon SageMaker JumpStart از راه اندازی زیرساخت برای استقرار این مدل از پیش آموزش دیده در محیط SageMaker مراقبت می کند.

مرحله 2 - استقرار Flan T5 XXL LLM با Amazon SageMaker JumpStart
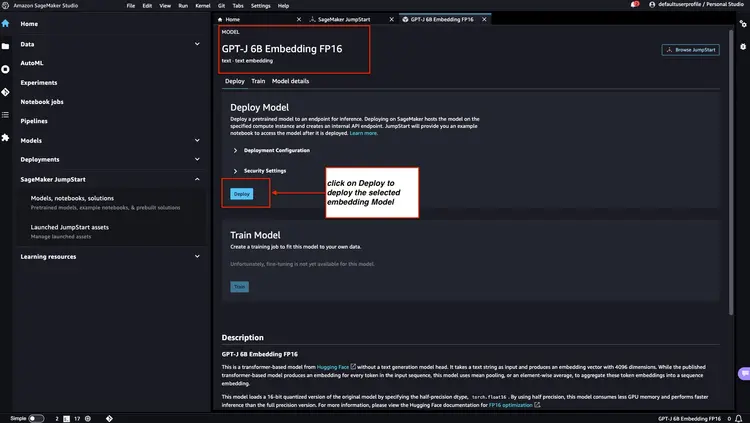
در مرحله بعد، در Amazon SageMaker JumpStart، Flan-T5 XXL LLM را انتخاب کنید، و سپس روی ‘Deploy’ کلیک کنید تا راه اندازی خودکار زیرساخت آغاز شود و نقطه پایانی مدل در محیط Amazon SageMaker مستقر شود.

مرحله 3 - وضعیت نقاط پایانی مدل مستقر شده را بررسی کنید
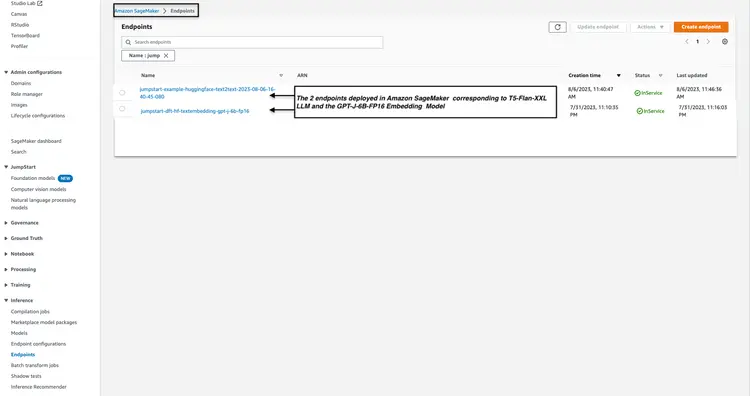
ما وضعیت نقاط پایانی مدل مستقر شده را از مرحله 1 و مرحله 2 در کنسول آمازون SageMaker بررسی می کنیم و نام نقطه پایانی آنها را یادداشت می کنیم، زیرا از آنها در کد خود استفاده خواهیم کرد. پس از استقرار نقاط پایانی مدل، کنسول من چگونه به نظر می رسد.

مرحله 4 – خوشه جستجوی باز آمازون را ایجاد کنید
Amazon OpenSearch یک سرویس جستجو و تجزیه و تحلیل است که از الگوریتم k-Nearest Neighbors (kNN) پشتیبانی می کند. این قابلیت برای جستجوهای مبتنی بر شباهت بسیار ارزشمند است و به ما این امکان را می دهد که از OpenSearch به عنوان یک پایگاه داده برداری به طور موثر استفاده کنیم. برای کاوش بیشتر و آشنایی با نسخههای Elasticsearch/OpenSearch که از افزونه kNN پشتیبانی میکنند، لطفاً به پیوند زیر مراجعه کنید: k-NN Plugin Documentation.
ما از AWS CLI برای استقرار فایل قالب AWS CloudFormation از مکان GitHub Infrastructure/opensearch-vectordb.yaml استفاده خواهیم کرد. دستور aws cloudformation create-stack را به صورت زیر برای ایجاد خوشه جستجوی باز آمازون اجرا کنید. قبل از اجرای دستور باید مقادیر خود را جایگزین username و password کنیم.
aws cloudformation create-stack --stack-name opensearch-vectordb \
--template-body file://opensearch-vectordb.yaml \
--parameters ParameterKey=ClusterName,ParameterValue=opensearch-vectordb \
ParameterKey=MasterUserName,ParameterValue=<username> \
ParameterKey=MasterUserPassword,ParameterValue=<password> مرحله 5 – گردش کار جذب و جاسازی سند را بسازید
در این مرحله، یک خط لوله جذب و پردازش ایجاد خواهیم کرد که برای خواندن یک سند PDF زمانی که در سطل سرویس ذخیره سازی ساده آمازون (S3) قرار می گیرد، طراحی شده است. این خط لوله وظایف زیر را انجام خواهد داد:
- متن را از سند PDF تکه تکه کنید.
- تکه های متن را به جاسازی (نمایش برداری) تبدیل کنید.
- جاسازی ها را در جستجوی باز آمازون ذخیره کنید.
انداختن یک فایل PDF در سطل S3 یک گردش کار مبتنی بر رویداد را آغاز می کند که شامل یک کار AWS Fargate است. این وظیفه وظیفه تبدیل متن به جاسازی و درج آنها در جستجوی باز آمازون خواهد بود.
نمای کلی نموداری
در زیر یک نمودار نشان دهنده خط لوله انتقال سند برای ذخیره سازی جاسازی تکه های متن در پایگاه داده برداری آمازون OpenSearch است:

اسکریپت راه اندازی و ساختار فایل
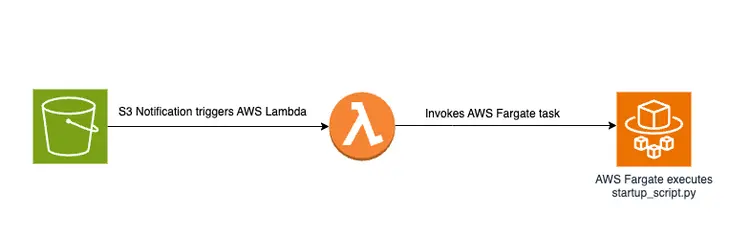
منطق اصلی در فایل create-embeddings-save-in-vectordb\startup_script.py قرار دارد. این اسکریپت پایتون، startup_script.py، چندین کار مربوط به پردازش اسناد، جاسازی متن، و درج در یک خوشه جستجوی باز آمازون را انجام می دهد. اسکریپت سند PDF را از سطل آمازون S3 دانلود می کند، سپس سند بارگیری شده به تکه های متنی کوچکتر تقسیم می شود. برای هر تکه، محتوای متنی به نقطه پایانی مدل GPT-J 6B FP16 Embedding مستقر در Amazon SageMaker (بازیابی شده از متغیر محیطی TEXT_EMBEDDING_MODEL_ENDPOINT_NAME) ارسال میشود تا جاسازیهای متنی ایجاد شود. تعبیههای ایجاد شده به همراه اطلاعات دیگر در فهرست جستجوی باز آمازون قرار میگیرند. این اسکریپت پارامترهای پیکربندی و اعتبار را از متغیرهای محیط بازیابی می کند و آن را برای محیط های مختلف سازگار می کند. این اسکریپت برای اجرای یکنواخت در یک ظرف Docker در نظر گرفته شده است.
تصویر Docker را بسازید و منتشر کنید
پس از درک کد در startup_script.py، ما به ساخت Dockerfile از پوشه create-embeddings-save-in-vectordb ادامه می دهیم و تصویر را به Amazon Elastic Container Registry (Amazon ECR) می بریم. Amazon Elastic Container Registry (Amazon ECR) یک رجیستری کانتینر کاملاً مدیریت شده است که میزبانی با کارایی بالا را ارائه می دهد، بنابراین ما می توانیم تصاویر و مصنوعات برنامه را به طور قابل اعتماد در هر مکانی مستقر کنیم. ما از AWS CLI و Docker CLI برای ساختن و انتقال تصویر Docker به Amazon ECR استفاده خواهیم کرد. در تمام دستورات زیر، <AWS Account Number> را با شماره حساب صحیح AWS جایگزین کنید.
یک نشانه احراز هویت را بازیابی کنید و کلاینت Docker را در رجیستری در AWS CLI احراز هویت کنید.
aws ecr get-login-password --region us-east-1 | docker login --username AWS --password-stdin <AWS Account Number>.dkr.ecr.us-east-1.amazonaws.com با استفاده از دستور زیر، تصویر Docker خود را بسازید.
docker build -t save-embedding-vectordb .
پس از اتمام ساخت، تصویر را تگ کنید تا بتوانیم تصویر را به این مخزن فشار دهیم:
docker tag save-embedding-vectordb:latest <AWS Account Number>.dkr.ecr.us-east-1.amazonaws.com/save-embedding-vectordb:latest
دستور زیر را برای فشار دادن این تصویر به مخزن جدید آمازون ECR اجرا کنید:
docker push <AWS Account Number>.dkr.ecr.us-east-1.amazonaws.com/save-embedding-vectordb:latest
هنگامی که تصویر Docker در مخزن آمازون ECR بارگذاری شد، باید شبیه تصویر زیر باشد:

زیرساختی برای گردش کار جاسازی PDF مبتنی بر رویداد بسازید
ما می توانیم از رابط خط فرمان AWS (AWS CLI) برای ایجاد پشته CloudFormation برای گردش کار مبتنی بر رویداد با پارامترهای ارائه شده استفاده کنیم. الگوی CloudFormation در مخزن GitHub در Infrastructure/fargate-embeddings-vectordb-save.yaml قرار دارد. برای مطابقت با محیط AWS باید پارامترها را نادیده بگیریم.
در اینجا پارامترهای کلیدی برای به روز رسانی در دستور aws cloudformation create-stack آمده است:
- BucketName: این پارامتر نشان دهنده سطل آمازون S3 است که در آن اسناد PDF را رها می کنیم.
- VpcId و SubnetId: این پارامترها مشخص می کنند که وظیفه Fargate در کجا اجرا می شود.
- ImageName: این نام تصویر Docker در رجیستری کانتینر الاستیک آمازون (ECR) برای save-embedding-vectordb است.
- TextEmbeddingModelEndpointName: از این پارامتر برای ارائه نام مدل Embedding مستقر در Amazon SageMaker در مرحله 1 استفاده کنید.
- VectorDatabaseEndpoint: آدرس نقطه پایانی دامنه OpenSearch آمازون را مشخص کنید.
- VectorDatabaseUsername و VectorDatabasePassword: این پارامترها برای اعتبارنامه های مورد نیاز برای دسترسی به خوشه جستجوی باز آمازون ایجاد شده در مرحله 4 هستند.
- VectorDatabaseIndex: نام ایندکس را در جستجوی باز آمازون که جاسازیهای سند PDF در آن ذخیره میشوند، تنظیم کنید.
برای اجرای ایجاد پشته CloudFormation، پس از بهروزرسانی مقادیر پارامتر، از دستور AWS CLI زیر استفاده میکنیم:
aws cloudformation create-stack \
--stack-name ecs-embeddings-vectordb \
--template-body file://fargate-embeddings-vectordb-save.yaml \
--parameters \
ParameterKey=BucketName,ParameterValue=car-manuals-12345 \
ParameterKey=VpcId,ParameterValue=vpc-123456 \
ParameterKey=SubnetId,ParameterValue=subnet-123456,subnet-123456 \
ParameterKey=Imagename,ParameterValue=123456.dkr.ecr.us-east-1.amazonaws.com/save-embedding-vectordb:latest \
ParameterKey=TextEmbeddingModelEndpointName,ParameterValue=jumpstart-dft-hf-textembedding-gpt-j-6b-fp16 \
ParameterKey=VectorDatabaseEndpoint,ParameterValue=https://search-cfnopensearch2-xxxxxxxx.us-east-1.es.amazonaws.com \
ParameterKey=VectorDatabaseUsername,ParameterValue=master \
ParameterKey=VectorDatabasePassword,ParameterValue=vectordbpassword \
ParameterKey=VectorDatabaseIndex,ParameterValue=carmanualبا ایجاد پشته CloudFormation فوق، یک سطل S3 راه اندازی می کنیم و اعلان های S3 را ایجاد می کنیم که عملکرد Lambda را راه اندازی می کند. این تابع لامبدا به نوبه خود یک کار Fargate را آغاز می کند. وظیفه Fargate یک کانتینر Docker را با فایل startup-script.py اجرا میکند که مسئول ایجاد جاسازیها در آمازون OpenSearch تحت یک فهرست OpenSearch جدید به نام carmanual است.
تست با یک نمونه PDF
هنگامی که پشته CloudFormation اجرا شد، یک پی دی اف که نشان دهنده کتابچه راهنمای ماشین است را در سطل S3 بیندازید. من یک کتابچه راهنمای ماشین را دانلود کردم که از اینجا موجود است. پس از اتمام اجرای خط لوله انتقال مبتنی بر رویداد، خوشه جستجوی باز آمازون باید شامل نمایه carmanual با جاسازیهایی باشد که در زیر نشان داده شده است.


مرحله 6 – API پرسش و پاسخ بلادرنگ را با پشتیبانی متنی Llm اجرا کنید
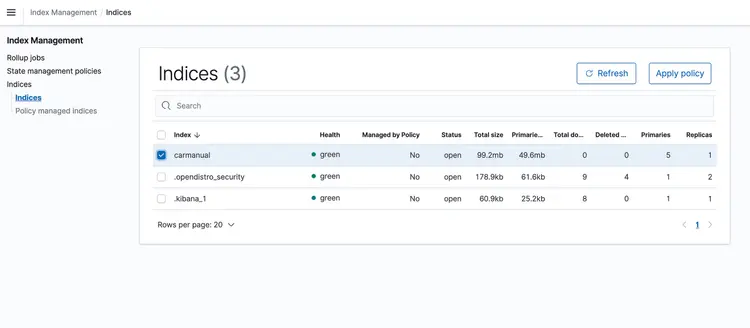
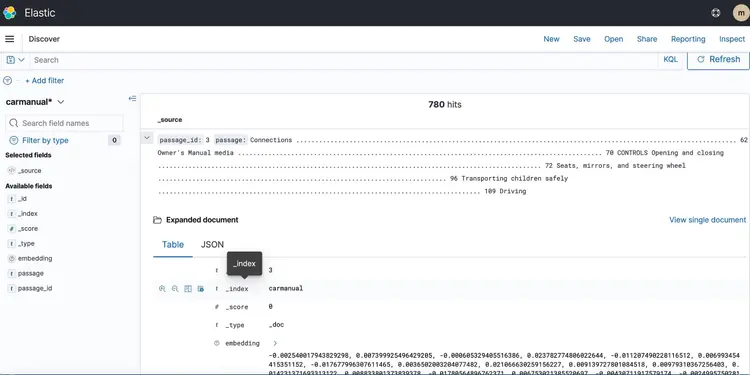
اکنون که جاسازیهای متنی خود را در پایگاه داده برداری داریم که توسط جستجوی باز آمازون پشتیبانی میشود، بیایید به مرحله بعدی برویم. در اینجا، ما از قابلیتهای T5 Flan XXL LLM برای ارائه پاسخهای بلادرنگ در مورد کتابچه راهنمای خودرو خود استفاده میکنیم.
ما از جاسازی های ذخیره شده در پایگاه داده برداری برای ارائه زمینه به LLM استفاده می کنیم. این زمینه LLM را قادر می سازد تا سوالات مربوط به کتابچه راهنمای خودرو ما را به طور موثر درک کند و به آنها پاسخ دهد. برای دستیابی به این هدف، ما از چارچوبی به نام LangChain استفاده خواهیم کرد که هماهنگی اجزای مختلف مورد نیاز برای سیستم پرسش و پاسخ متن آگاه ما در زمان واقعی را که توسط LLM طراحی شده است، ساده می کند.
جاسازی های ذخیره شده در پایگاه داده برداری معانی و روابط کلمات را به تصویر می کشد و به ما امکان می دهد محاسبات را بر اساس شباهت های معنایی انجام دهیم. در حالی که تعبیهها بازنماییهای برداری از تکههای متن را برای گرفتن معانی و روابط ایجاد میکنند، T5 Flan LLM در ایجاد پاسخهای مرتبط با زمینه بر اساس زمینه تزریق شده به درخواستها و پرس و جوها تخصص دارد. هدف این است که سوالات کاربر را با تکه های متن با ایجاد جاسازی برای سوالات و سپس اندازه گیری شباهت آنها با سایر جاسازی های ذخیره شده در پایگاه داده برداری مقایسه کنیم.
با نمایش تکههای متن و سؤالات کاربر بهعنوان بردار، میتوانیم محاسبات ریاضی را برای انجام جستجوهای شباهت آگاه از زمینه انجام دهیم. برای سنجش شباهت بین دو نقطه داده، از متریک های فاصله در یک فضای چند بعدی استفاده می کنیم.
نمودار زیر گردش کار پرسش و پاسخ بلادرنگ را نشان می دهد که توسط LangChain و T5 Flan LLM ما ارائه شده است.
بررسی اجمالی نموداری پشتیبانی پرسش و پاسخ Realtime از T5-Flan-XXL LLM

API را بسازید
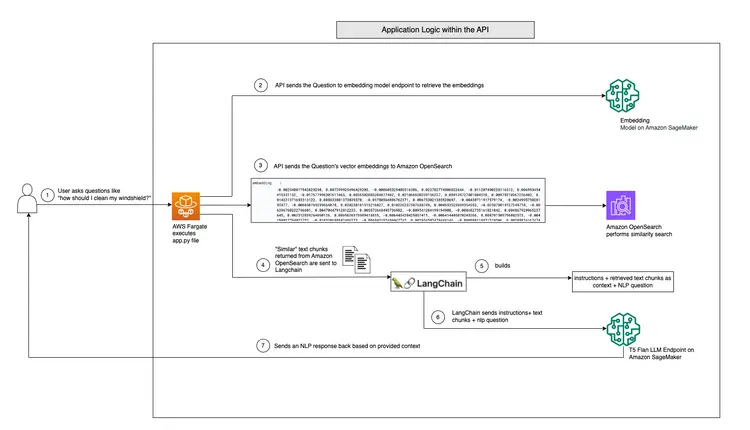
اکنون که گردش کار LangChain و T5 Flan LLM خود را بررسی کردهایم، بیایید به کد API خود بپردازیم، که سؤالات کاربر را میپذیرد و پاسخهای آگاه از زمینه را ارائه میدهد. این API پرسش و پاسخ بلادرنگ در پوشه RAG-langchain-questionanswer-t5-llm مخزن GitHub ما قرار دارد و منطق اصلی آن در فایل app.py قرار دارد. این برنامه مبتنی بر Flask یک مسیر /qa را برای پاسخگویی به سوال تعریف می کند.
هنگامی که کاربر سؤالی را به API ارسال می کند، از متغیر محیطی TEXT_EMBEDDING_MODEL_ENDPOINT_NAME استفاده می کند و به نقطه پایانی Amazon SageMaker اشاره می کند تا سؤال را به نمایش های برداری عددی به نام جاسازی تبدیل کند. این تعبیهها معنای معنایی متن را به تصویر میکشند.
API بیشتر از آمازون OpenSearch برای اجرای جستجوهای شباهت آگاه از زمینه استفاده می کند، و آن را قادر می سازد تا تکه های متن مربوطه را از راهنمای کار فهرست OpenSearch بر اساس جاسازی های به دست آمده از پرس و جوهای کاربر واکشی کند. پس از این مرحله، API نقطه پایانی T5 Flan LLM را که با متغیر محیطی T5FLAN_XXL_ENDPOINT_NAME نشان داده شده است، که در Amazon SageMaker نیز مستقر شده است، فراخوانی می کند. نقطه پایانی از تکه های متن بازیابی شده از آمازون OpenSearch به عنوان زمینه برای تولید پاسخ ها استفاده می کند. این تکههای متنی که از آمازون OpenSearch به دست آمدهاند، بهعنوان زمینهای ارزشمند برای نقطه پایانی T5 Flan LLM عمل میکنند و به آن اجازه میدهند تا پاسخهای معناداری به درخواستهای کاربر ارائه دهد. کد API از LangChain برای هماهنگ کردن همه این تعاملات استفاده می کند.
تصویر Docker را برای API بسازید و منتشر کنید
پس از درک کد در app.py، ما به ساخت Dockerfile از پوشه RAG-langchain-questionanswer-t5-llm ادامه می دهیم و تصویر را به Amazon ECR فشار می دهیم. ما از AWS CLI و Docker CLI برای ساختن و انتقال تصویر Docker به Amazon ECR استفاده خواهیم کرد. در تمام دستورات زیر، <AWS Account Number> را با شماره حساب صحیح AWS جایگزین کنید.
یک نشانه احراز هویت را بازیابی کنید و کلاینت Docker را در رجیستری در AWS CLI احراز هویت کنید.
aws ecr get-login-password --region us-east-1 | docker login --username AWS --password-stdin <AWS Account Number>.dkr.ecr.us-east-1.amazonaws.com
با استفاده از دستور زیر تصویر داکر را بسازید.
docker build -t qa-container .
پس از اتمام ساخت، تصویر را تگ کنید تا بتوانیم تصویر را به این مخزن فشار دهیم:
docker tag qa-container:latest <AWS Account Number>.dkr.ecr.us-east-1.amazonaws.com/qa-container:latest
دستور زیر را برای فشار دادن این تصویر به مخزن جدید آمازون ECR اجرا کنید:
docker push <AWS Account Number>.dkr.ecr.us-east-1.amazonaws.com/qa-container:latest
هنگامی که تصویر Docker در مخزن آمازون ECR بارگذاری شد، باید شبیه تصویر زیر باشد:

پشته CloudFormation را برای میزبانی نقطه پایانی API بسازید
ما از رابط خط فرمان AWS (CLI) برای ایجاد پشته CloudFormation برای آمازون ECS Cluster استفاده می کنیم که میزبان یک وظیفه Fargate برای افشای API است. الگوی CloudFormation در مخزن GitHub در Infrastructure/fargate-api-rag-llm-langchain.yaml قرار دارد. برای مطابقت با محیط AWS باید پارامترها را نادیده بگیریم. در اینجا پارامترهای کلیدی برای به روز رسانی در دستور aws cloudformation create-stack آمده است:
- DemoVPC: این پارامتر ابر خصوصی مجازی (VPC) را مشخص می کند که سرویس شما در آن اجرا می شود.
- PublicSubnetIds: این پارامتر به لیستی از شناسه های زیرشبکه عمومی نیاز دارد که در آن متعادل کننده بار و وظایف شما قرار می گیرد.
- IMAGENAME: نام تصویر Docker را در رجیستری کانتینر الاستیک آمازون (ECR) برای کانتینر qa ارائه دهید.
- TextEmbeddingModelEndpointName: نام نقطه پایانی مدل Embeddings مستقر در Amazon SageMaker را در مرحله 1 مشخص کنید.
- T5FlanXXLEndpointName: نام نقطه پایانی T5-FLAN مستقر در آمازون SageMaker را در مرحله 2 تنظیم کنید.
- VectorDatabaseEndpoint: آدرس نقطه پایانی دامنه OpenSearch آمازون را مشخص کنید.
- VectorDatabaseUsername و VectorDatabasePassword: این پارامترها برای اعتبار مورد نیاز برای دسترسی به OpenSearch Cluster ایجاد شده در مرحله 4 هستند.
- VectorDatabaseIndex: نام ایندکس را در آمازون OpenSearch که داده های سرویس شما در آن ذخیره می شود، تنظیم کنید. نام شاخصی که در این مثال استفاده کرده ایم carmanual است.
برای اجرای ایجاد پشته CloudFormation، پس از بهروزرسانی مقادیر پارامتر، از دستور AWS CLI زیر استفاده میکنیم:
aws cloudformation create-stack \
--stack-name ecs-questionanswer-llm \
--template-body file://fargate-api-rag-llm-langchain.yaml \
--parameters \
ParameterKey=DemoVPC,ParameterValue=vpc-123456 \
ParameterKey=PublicSubnetIds,ParameterValue=subnet-123456,subnet-789012 \
ParameterKey=Imagename,ParameterValue=123456.dkr.ecr.us-east-1.amazonaws.com/qa-container:latest \
ParameterKey=TextEmbeddingModelEndpointName,ParameterValue=jumpstart-dft-hf-textembedding-gpt-j-6b-fp16 \
ParameterKey=T5FlanXXLEndpointName,ParameterValue=jumpstart-example-huggingface-text2text-2023-08-06-16-40-45-080 \
ParameterKey=VectorDatabaseEndpoint,ParameterValue=https://search-cfnopensearch2-xxxxxxxx.us-east-1.es.amazonaws.com \
ParameterKey=VectorDatabaseUsername,ParameterValue=master \
ParameterKey=VectorDatabasePassword,ParameterValue=vectordbpassword \
ParameterKey=VectorDatabaseIndex,ParameterValue=carmanualپس از اجرای موفقیت آمیز پشته CloudFormation ذکر شده در بالا، به کنسول AWS بروید و به برگه ‘CloudFormation Outputs’ برای پشته ecs-questionanswer-llm دسترسی پیدا کنید. در این تب اطلاعات ضروری از جمله نقطه پایانی API را خواهیم یافت. در زیر نمونه ای از شباهت خروجی آورده شده است:

API را تست کنید
ما می توانیم نقطه پایانی API را از طریق دستور curl به صورت زیر آزمایش کنیم:
curl -X POST -H "Content-Type: application/json" -d '{"question":"How can I clean my windshield?"}' http://quest-Publi-abc-xxxx.us-east-1.elb.amazonaws.com/qa
ما پاسخی را مانند شکل زیر خواهیم دید
{"response":"To clean sensors and camera lenses, use a cloth moistened with a small amount of glass detergent."}
مرحله 7 – ایجاد و استقرار وب سایت با چت بات یکپارچه
سپس به آخرین مرحله برای خط لوله کامل پشته خود می رویم، که API را با ربات چت تعبیه شده در یک وب سایت HTML یکپارچه می کند. برای این وب سایت و ربات چت تعبیه شده، کد منبع ما یک برنامه Nodejs است که از یک index.html یکپارچه شده با botkit.js منبع باز به عنوان ربات چت تشکیل شده است. برای آسان کردن کار، یک Dockerfile ایجاد کردهام و آن را در کنار کد موجود در پوشه homegrown_website_and_bot ارائه کردهام. ما از AWS CLI و Docker CLI برای ساختن و ارسال Docker Image به Amazon ECR برای وبسایت فرانتاند استفاده خواهیم کرد. در تمام دستورات زیر، <AWS Account Number> را با شماره حساب صحیح AWS جایگزین کنید.
یک نشانه احراز هویت را بازیابی کنید و کلاینت Docker را در رجیستری در AWS CLI احراز هویت کنید.
aws ecr get-login-password --region us-east-1 | docker login --username AWS --password-stdin <AWS Account Number>.dkr.ecr.us-east-1.amazonaws.com
با استفاده از دستور زیر تصویر Docker را بسازید:
docker build -t web-chat-frontend .
پس از اتمام ساخت، تصویر را تگ کنید تا بتوانیم تصویر را به این مخزن فشار دهیم:
docker tag web-chat-frontend:latest <AWS Account Number>.dkr.ecr.us-east-1.amazonaws.com/web-chat-frontend:latest
دستور زیر را برای فشار دادن این تصویر به مخزن جدید آمازون ECR اجرا کنید:
docker push <AWS Account Number>.dkr.ecr.us-east-1.amazonaws.com/web-chat-frontend:latest
پس از اینکه تصویر Docker برای وبسایت به مخزن ECR فرستاده شد، با اجرای فایل Infrastructure\fargate-website-chatbot.yaml پشته CloudFormation را برای قسمت جلویی میسازیم. برای مطابقت با محیط AWS باید پارامترها را نادیده بگیریم. در اینجا پارامترهای کلیدی برای به روز رسانی در دستور aws cloudformation create-stack آمده است:
- DemoVPC: این پارامتر ابر خصوصی مجازی (VPC) را مشخص می کند که در آن وب سایت شما مستقر می شود.
- PublicSubnetIds: این پارامتر به لیستی از شناسه های زیرشبکه عمومی نیاز دارد که در آن متعادل کننده بار و وظایف وب سایت شما قرار می گیرد.
- IMAGENAME: نام تصویر Docker را در رجیستری کانتینر الاستیک آمازون (ECR) برای وب سایت خود وارد کنید.
- QUESTURL: URL نقطه پایانی API مستقر در مرحله 6 را مشخص کنید. فرمت آن http://<DNS Name of API ALB>/qa است.
برای اجرای ایجاد پشته CloudFormation، پس از بهروزرسانی مقادیر پارامتر، از دستور AWS CLI زیر استفاده میکنیم:
aws cloudformation create-stack \
--stack-name ecs-website-chatbot \
--template-body file://fargate-website-chatbot.yaml \
--parameters \
ParameterKey=DemoVPC,ParameterValue=vpc-12345 \
ParameterKey=PublicSubnetIds,ParameterValue=subnet-1,subnet-2 \
ParameterKey=Imagename,ParameterValue=123456.dkr.ecr.us-east-1.amazonaws.com/web-chat-frontend:latest \
ParameterKey=QUESTURL,ParameterValue=http://your-api-alb-dns-name/qaمرحله 8 – دستیار هوش مصنوعی Car Savvy را بررسی کنید
پس از ساخت موفقیت آمیز پشته CloudFormation که در بالا ذکر شد، به کنسول AWS بروید و به برگه CloudFormation Outputs برای پشته ecs-website-chatbot دسترسی پیدا کنید. در این تب ما نام DNS Application Load Balancer (ALB) مرتبط با قسمت جلویی را پیدا خواهیم کرد. در زیر نمونه ای از شباهت خروجی آورده شده است:
URL نقطه پایانی را در مرورگر فراخوانی کنید تا ببینید وب سایت چگونه به نظر می رسد. سوالات زبان طبیعی را از چت بات تعبیه شده بپرسید. برخی از سوالاتی که می توانیم بپرسیم این است – “چگونه باید شیشه جلو را تمیز کنم؟” ، “کجا می توانم VIN را پیدا کنم؟”، “چگونه باید نقص ایمنی را گزارش کنم؟”
بعد چی؟

امیدواریم موارد بالا به شما نشان دهد که چگونه می توانید خطوط لوله آماده تولید خود را برای LLM ها بسازید و خط لوله را با ربات های چت جلویی و NLP تعبیه شده خود ادغام کنید. چیزهای دیگری را که میخواهید درباره استفاده از فناوریهای منبع باز، تجزیه و تحلیل، یادگیری ماشین و AWS بخوانید، به من اطلاع دهید!
همانطور که به سفر یادگیری خود ادامه می دهید، من شما را تشویق می کنم که عمیق تر در Embeddings، Vector Databases، LangChain و چندین LLM دیگر کاوش کنید. آنها در Amazon SageMaker JumpStart و همچنین ابزارهای AWS که ما در این آموزش استفاده کردیم مانند Amazon OpenSearch، Docker Containers، Fargate در دسترس هستند. در اینجا چند مرحله بعدی برای کمک به تسلط بر این فناوری ها آورده شده است:
- Amazon SageMaker: همانطور که با SageMaker پیشرفت می کنید، با الگوریتم های دیگری که ارائه می دهد آشنا شوید.
- AMAZON-OPENSEARCH: با الگوریتم K-NN و سایر الگوریتم های فاصله آشنا شوید
- Langchain: LangChain چارچوبی است که برای ساده سازی ایجاد برنامه ها با استفاده از LLM طراحی شده است.
- Embeddings: تعبیه نمایش عددی یک قطعه اطلاعات است، به عنوان مثال، متن، اسناد، تصاویر، صدا و غیره.
- Amazon SageMaker JumpStart: SageMaker JumpStart مدل های از پیش آموزش دیده و منبع باز را برای طیف گسترده ای از انواع مشکلات ارائه می دهد تا به شما در شروع یادگیری ماشین کمک کند.
پاک کردن
- به AWS CLI وارد شوید. مطمئن شوید که AWS CLI به درستی با مجوزهای لازم برای انجام این اقدامات پیکربندی شده است.
- با اجرای دستور زیر فایل PDF را از سطل آمازون S3 حذف کنید. نام سطل خود را با نام واقعی سطل آمازون S3 خود جایگزین کنید و در صورت نیاز مسیر فایل PDF خود را تنظیم کنید.
aws s3 rm s3://your-bucket-name/path/to/your-pdf-file.pdf
پشته های CloudFormation را حذف کنید. نام پشته ها را با نام های واقعی پشته های CloudFormation خود جایگزین کنید.
# Delete 'ecs-website-chatbot' stack
aws cloudformation delete-stack --stack-name ecs-website-chatbot
# Delete 'ecs-questionanswer-llm' stack
aws cloudformation delete-stack --stack-name ecs-questionanswer-llm
# Delete 'ecs-embeddings-vectordb' stack
aws cloudformation delete-stack --stack-name ecs-embeddings-vectordb
# Delete 'opensearch-vectordb' stack
aws cloudformation delete-stack --stack-name opensearch-vectordb# Delete SageMaker endpoint 1
aws sagemaker delete-endpoint --endpoint-name endpoint-name-1
# Delete SageMaker endpoint 2
aws sagemaker delete-endpoint --endpoint-name endpoint-name-2نتیجه
در این آموزش، ما یک چت ربات پرسش و پاسخ تمام پشته با استفاده از فناوریهای AWS و ابزارهای منبع باز ساختیم. ما از آمازون OpenSearch به عنوان یک پایگاه داده برداری، مدل جاسازی GPT-J 6B FP16 را یکپارچه کردیم و از Langchain با یک LLM استفاده کردیم. این ربات چت بینش هایی را از اسناد بدون ساختار استخراج می کند.









