
مقدمه
DeepSeek R1، به دلایل خوب، جامعه AI/ML را در هفته های گذشته طوفان کرده است، و حتی در واقع فراتر از آن به جهان گسترده تر گسترش یافته است و تأثیرات عمده ای بر اقتصاد و سیاست دارد. این بیشتر به دلیل ماهیت منبع باز مجموعه مدل و قیمت فوقالعاده پایین آموزش است، که به جامعه بیشتر نشان داده است که آموزش مدلهای SOTA AI تقریباً به سرمایه یا تحقیقات اختصاصی زیادی که قبلاً تصور میشد نیاز ندارد.
در قسمت اول این مجموعه، DeepSeek R1 را معرفی کردیم و نحوه اجرای مدل با استفاده از Olama را نشان دادیم. در این پیگیری، ما با یک فرو رفتن عمیق تر در مورد آنچه که R1 را واقعاً خاص می کند، شروع خواهیم کرد. ما بر تجزیه و تحلیل الگوی منحصر به فرد یادگیری تقویتی (RL) مدل تمرکز خواهیم کرد تا ببینیم که چگونه قابلیتهای استدلالی LLMها را میتوان صرفاً از طریق RL تشویق کرد، و پس از آن، در مورد اینکه چگونه تقطیر این تکنیکها به مدلهای دیگر به ما اجازه میدهد تا این قابلیتها را با نسخههای موجود به اشتراک بگذاریم. ما با یک نمایش کوتاه در مورد نحوه راه اندازی و اجرای مدل های DeepSeek R1 با GPU Droplets با استفاده از 1-Click Model GPU Droplets به پایان خواهیم رسید.
پیش نیازها
- یادگیری عمیق: این مقاله به موضوعات متوسط تا پیشرفته مرتبط با آموزش شبکه های عصبی و یادگیری تقویتی می پردازد.
- حساب DigitalOcean: ما به طور خاص از DigitalOcean’s HuggingFace 1-Click Model GPU Droplets برای آزمایش R1 استفاده خواهیم کرد.
بررسی اجمالی DeepSeek R1
هدف پروژه تحقیقاتی DeepSeek R1 بازآفرینی قابلیتهای استدلال موثر نشان داده شده توسط مدلهای استدلال قدرتمند، یعنی O1 OpenAI بود. برای رسیدن به این هدف، آنها به دنبال بهبود کار موجود خود، DeepSeek-v3-Base، با استفاده از یادگیری تقویتی خالص بودند. این منجر به ظهور DeepSeek R1 Zero شد که عملکرد فوقالعادهای را در معیارهای استدلال نشان میدهد، اما فاقد قابلیت تفسیر انسانی است و برخی رفتارهای غیرعادی مانند اختلاط زبان را نشان میدهد.
برای بهبود این مشکلات، DeepSeek R1 را پیشنهاد کردند که شامل مقدار کمی از داده های شروع سرد و یک خط لوله آموزشی چند مرحله ای است. R1 با تنظیم دقیق مدل DeepSeek-v3-Base بر روی هزاران نمونه داده شروع سرد، سپس اجرای دور دیگری از یادگیری تقویتی، و به دنبال انجام تنظیم دقیق نظارت شده بر روی مجموعه داده استدلالی، و در نهایت با پایان دادن به دور نهایی یادگیری تقویتی، به خوانایی و کاربرد SOTA LLM دست یافت. آنها سپس این تکنیک را با نظارت بر تنظیم دقیق آنها بر روی داده های جمع آوری شده از R1 به مدل های دیگر تقطیر کردند.
برای بررسی عمیقتر این مراحل توسعه، و بحث در مورد چگونگی بهبود مدل به طور مکرر برای رسیدن به قابلیتهای DeepSeek R1، همراه باشید.
آموزش DeepSeek R1 Zero
برای ایجاد DeepSeek R1 Zero، مدل پایه ای که R1 از آن توسعه یافته است، محققان RL را مستقیماً بدون هیچ داده SFT روی مدل پایه اعمال کردند. پارادایم RL انتخابی آنها بهینه سازی خط مشی نسبی گروهی (GRPO) نامیده می شود. این فرآیند از مقاله DeepSeekMath اقتباس شده است.
GRPO شبیه به سیستم های آشنا و دیگر RL است، اما از یک جهت مهم متفاوت است: از مدل انتقادی استفاده نمی کند. در عوض، GRPO خط پایه را از نمرات گروه تخمین می زند. مدلسازی پاداش دو قانون برای این سیستم دارد که هر کدام به دقت و پایبندی قالب به یک الگو پاداش میدهد. سپس پاداش به عنوان منبع سیگنال آموزشی عمل می کند که سپس برای تغییر جهت بهینه سازی RL استفاده می شود. این سیستم مبتنی بر قانون به فرآیند RL اجازه می دهد تا مدل را به طور مکرر اصلاح و بهبود بخشد.

خود قالب آموزشی یک فرمت نوشتاری ساده است که مدل پایه را راهنمایی میکند تا مطابق با بالا دستورالعملهای مشخص شده ما را رعایت کند. این مدل پاسخها به «اعلان» تنظیمشده را برای هر مرحله از RL اندازهگیری میکند. “این یک دستاورد قابل توجه است، زیرا بر توانایی مدل برای یادگیری و تعمیم موثر تنها از طریق RL تاکید می کند” (منبع).
این خود تکاملی مدل، آن را به توسعه قابلیتهای استدلال قدرتمند خود، از جمله بازتاب خود و در نظر گرفتن رویکردهای جایگزین، سوق میدهد. این با یک لحظه در طول آموزش تقویت می شود که تیم تحقیقاتی مدل را “لحظه آها” می نامند. در طول این مرحله، DeepSeek-R1-Zero یاد می گیرد که با ارزیابی مجدد رویکرد اولیه خود، زمان تفکر بیشتری را به یک مشکل اختصاص دهد. این رفتار نه تنها گواهی بر توانایی های استدلالی رو به رشد مدل است، بلکه نمونه ای جذاب از این است که چگونه یادگیری تقویتی می تواند منجر به نتایج غیرمنتظره و پیچیده شود.» (منبع).
DeepSeek R1 Zero در بین معیارها بسیار خوب عمل کرد، اما از نظر خوانایی و کاربرد در مقایسه با LLM های مناسب و سازگار با انسان، به شدت آسیب دید. بنابراین تیم تحقیقاتی DeepSeek R1 را برای بهبود بهتر مدل برای وظایف سطح انسانی پیشنهاد کرد.
از DeepSeek R1 Zero تا DeepSeek R1
برای رفتن از DeepSeek R1 Zero نسبتاً رام نشده به DeepSeek R1 بسیار کاربردی تر، محققان چندین مرحله آموزشی را معرفی کردند.
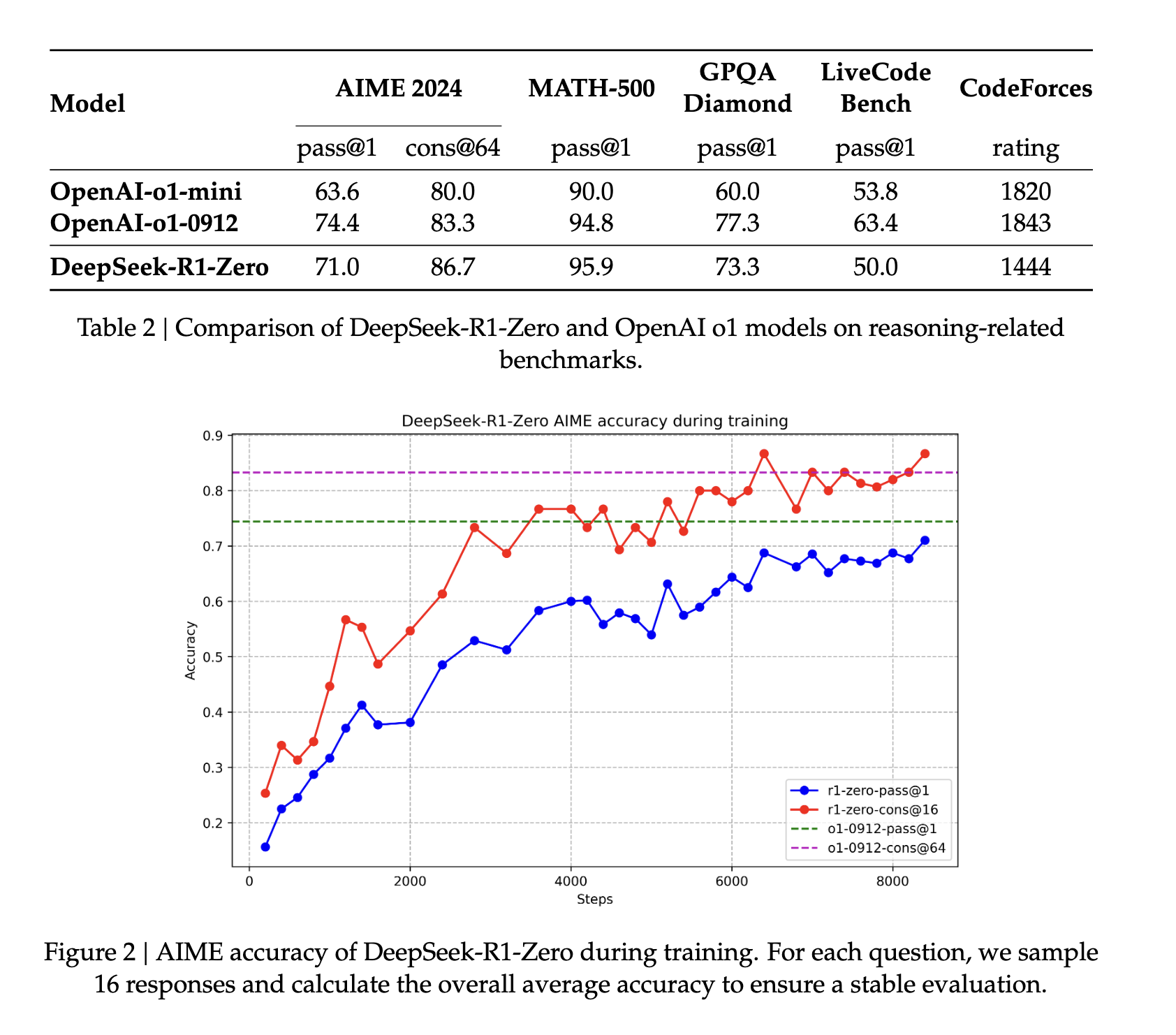
برای شروع، DeepSeek-v3-Base بر روی هزاران قطعه داده شروع سرد قبل از شروع همان پارادایم RL مورد استفاده برای DeepSeek R1 Zero با پاداش اضافی برای زبان سازگار در خروجی ها به خوبی تنظیم شد. در عمل، این مرحله برای افزایش قابلیتهای استدلال مدل، بهویژه در کارهای مستدل مانند کدنویسی، ریاضیات، علوم و استدلال منطقی، که شامل مسائل کاملاً تعریف شده با راهحلهای واضح است، کار میکند (منبع).
هنگامی که این مرحله RL کامل شد، از مدل حاصل برای جمع آوری داده های جدید برای تنظیم دقیق نظارت شده استفاده می کنند. «برخلاف دادههای شروع سرد اولیه، که عمدتاً بر استدلال تمرکز میکند، این مرحله دادههایی را از حوزههای دیگر ترکیب میکند تا قابلیتهای مدل را در نوشتن، ایفای نقش و سایر کارهای همهمنظور افزایش دهد» (منبع).
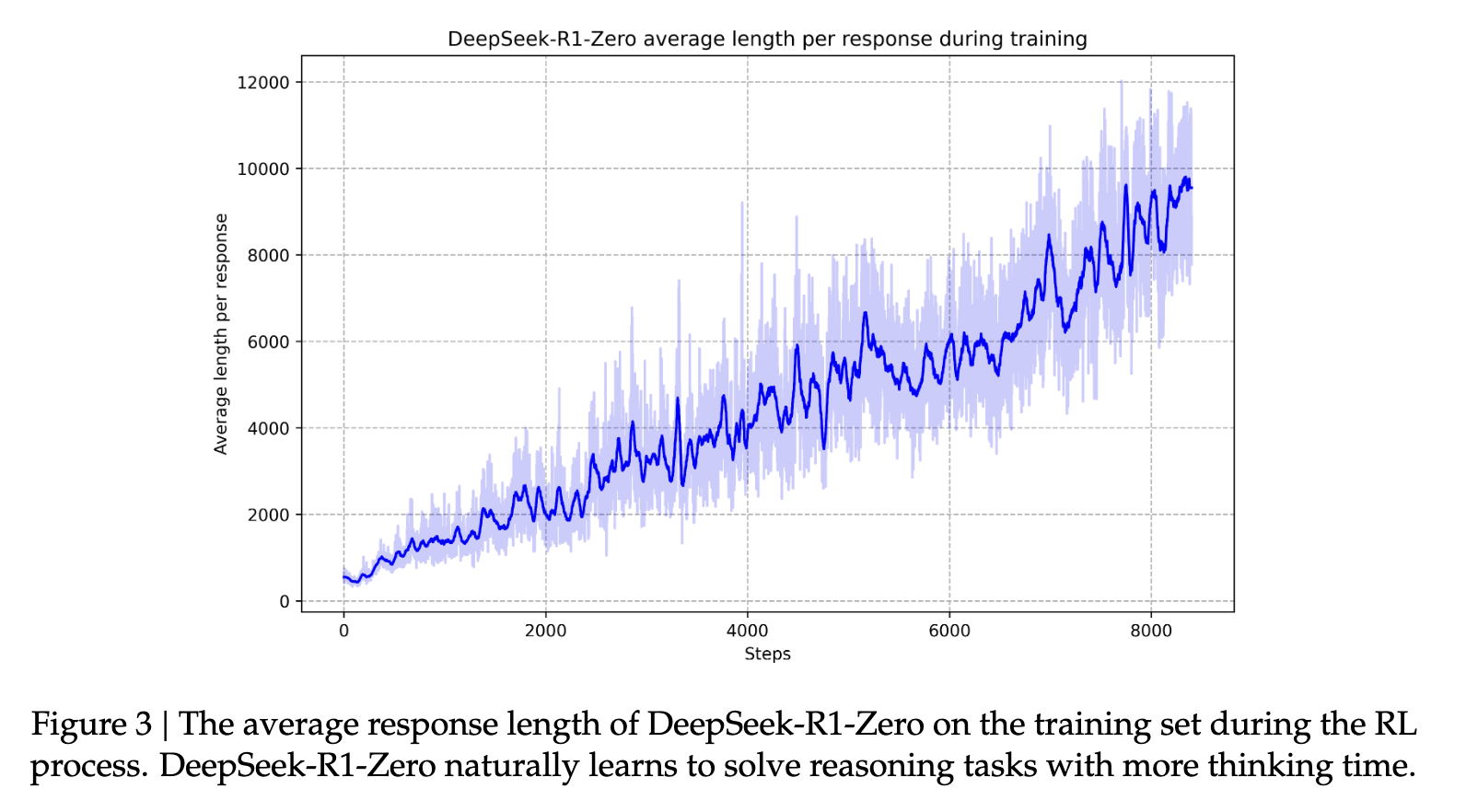
در مرحله بعد، مرحله دوم RL برای بهبود “مفید بودن و بی ضرر بودن مدل در حالی که به طور همزمان قابلیت های استدلال آن را اصلاح می کند” اجرا می شود (منبع). با آموزش بیشتر مدل بر روی توزیعهای سریع متنوع با سیگنالهای پاداش، آنها میتوانند مدلی را تربیت کنند که در استدلال برتری داشته باشد و در عین حال مفید بودن و بیضرر بودن را در اولویت قرار دهد. این به پاسخگویی “مانند انسان” مدل ها کمک می کند. این به مدل کمک می کند تا قابلیت های استدلال باورنکردنی را که به آن شناخته شده است، تکامل دهد. با گذشت زمان، این فرآیند به مدل کمک می کند تا زنجیره های بلند مشخصه فکر و استدلال خود را توسعه دهد.
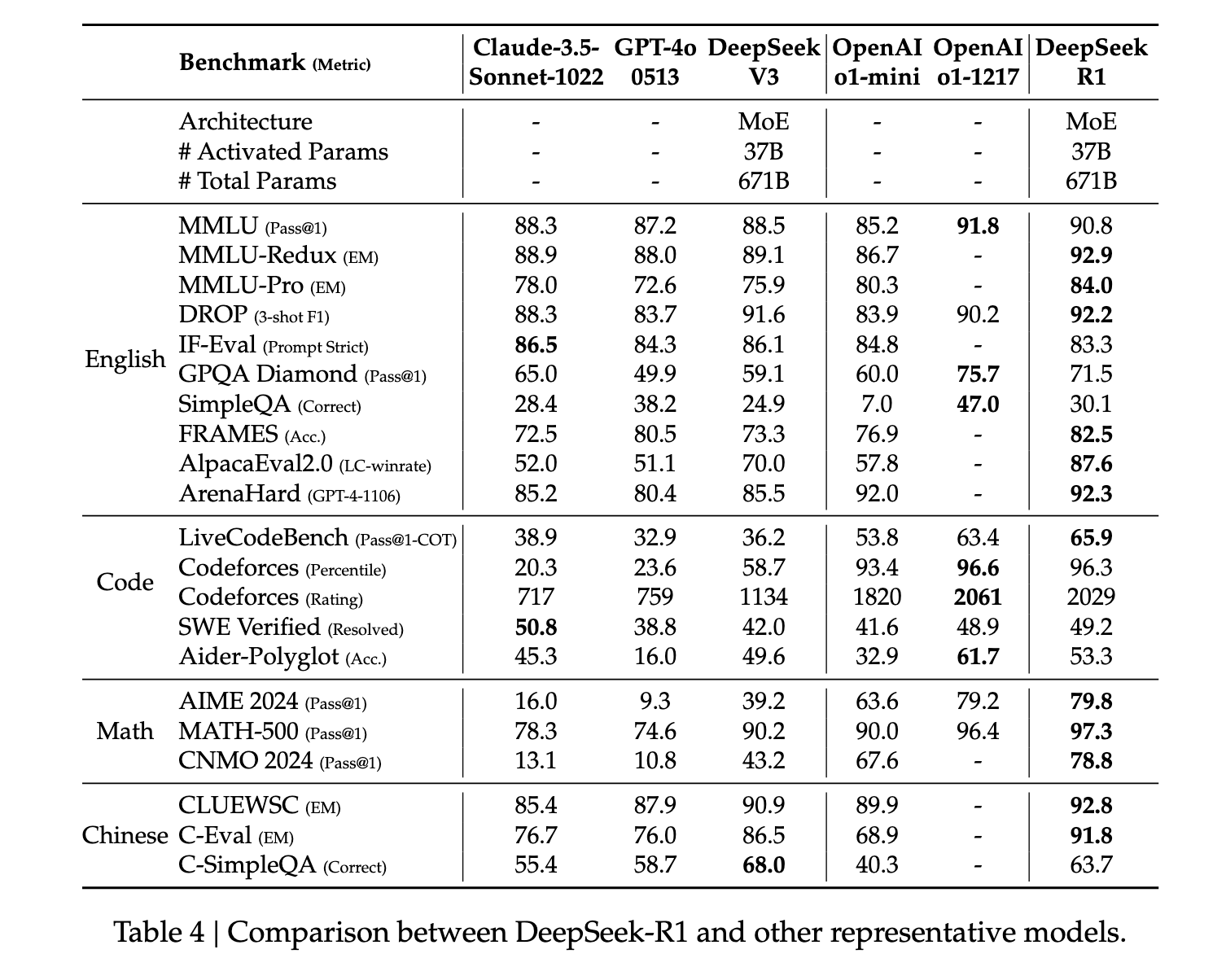
در سراسر صفحه، R1 عملکرد هنر را در معیارهای استدلال نشان می دهد. در برخی از وظایف، مانند ریاضی، حتی نشان داده است که از معیارهای منتشر شده برای O1 بهتر عمل می کند. به طور کلی، عملکرد بسیار بالایی در سوالات مربوط به ساقه نیز وجود دارد که در درجه اول به یادگیری تقویتی در مقیاس بزرگ نسبت داده می شود. علاوه بر موضوعات STEM، این مدل در پاسخ به سؤالات، وظایف آموزشی و استدلال پیچیده مهارت بالایی دارد. نویسندگان استدلال میکنند که این پیشرفتها و قابلیتهای افزایشیافته مدیون تکامل مدلهای پردازش زنجیرهای فکر از طریق یادگیری تقویتی است. دادههای زنجیره بلند فکر در طول یادگیری تقویتی و تنظیم دقیق برای تشویق مدل به ارائه خروجیهای طولانیتر و دروننگرتر استفاده میشود.
مدل های تقطیر شده DeepSeek R1
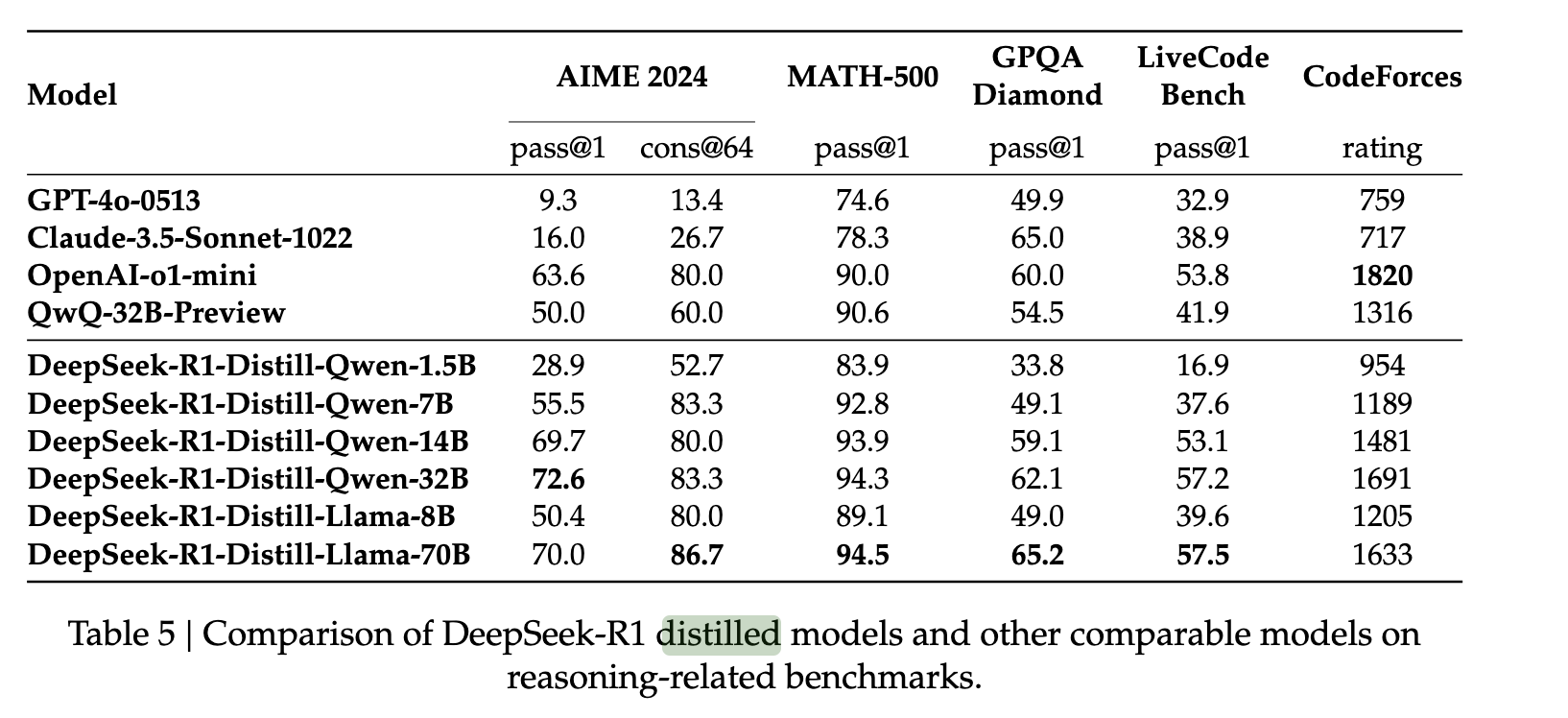 برای گسترش قابلیتهای DeepSeek R1 به مدلهای کوچکتر، نویسندگان 800000 نمونه از DeepSeek R1 جمعآوری کردند و از آنها برای تنظیم دقیق مدلهایی مانند QWEN و LLAMA استفاده کردند. آنها دریافتند که این روش تقطیر نسبتاً مستقیم امکان انتقال قابلیتهای استدلال R1 را به این مدلهای جدید با درجه بالایی از موفقیت فراهم میکند. آنها این کار را بدون هیچ RL اضافی انجام دادند و قدرت پاسخ های مدل های اصلی را برای انجام تقطیر مدل نشان دادند.
برای گسترش قابلیتهای DeepSeek R1 به مدلهای کوچکتر، نویسندگان 800000 نمونه از DeepSeek R1 جمعآوری کردند و از آنها برای تنظیم دقیق مدلهایی مانند QWEN و LLAMA استفاده کردند. آنها دریافتند که این روش تقطیر نسبتاً مستقیم امکان انتقال قابلیتهای استدلال R1 را به این مدلهای جدید با درجه بالایی از موفقیت فراهم میکند. آنها این کار را بدون هیچ RL اضافی انجام دادند و قدرت پاسخ های مدل های اصلی را برای انجام تقطیر مدل نشان دادند.
راه اندازی DeepSeek R1 در GPU Droplets
راه اندازی DeepSeek R1 در GPU Droplets بسیار ساده است اگر از قبل یک حساب DigitalOcean دارید. قبل از ادامه، حتما وارد سیستم شوید.
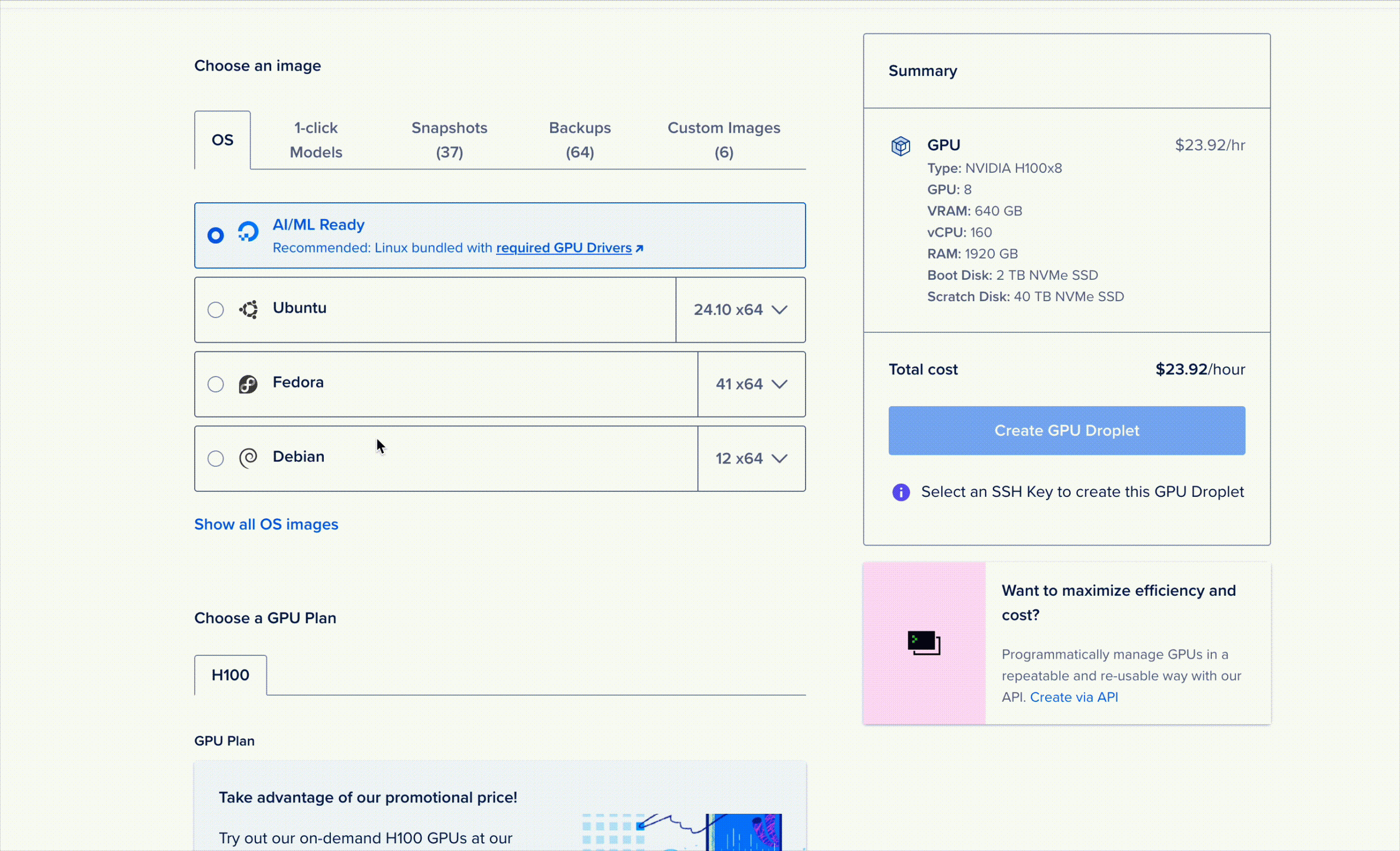
ما دسترسی به R1 را به عنوان یک قطره GPU مدل 1-Click ارائه می دهیم. برای راهاندازی آن، به سادگی کنسول GPU Droplet را باز کنید، به تب «1-Click Models» در پنجره انتخاب الگو بروید و دستگاه را راهاندازی کنید!
از آنجا، مدل با پیروی از روشهای HuggingFace یا OpenAI برای برقراری ارتباط با مدل قابل دسترسی خواهد بود. از اسکریپت زیر برای تعامل با مدل خود با کد پایتون استفاده کنید.
import os
from huggingface_hub import InferenceClient
client = InferenceClient(base_url="http://localhost:8080", api_key=os.getenv("BEARER_TOKEN"))
chat_completion = client.chat.completions.create(
messages=[
{"role":"user","content":"What is Deep Learning?"},
],
temperature=0.7,
top_p=0.95,
max_tokens=128,
)
## or use OpenAI formatting
#import os
#from openai import OpenAI
#
#client = OpenAI(base_url="http://localhost:8080/v1/", api_key=os.getenv("BEARER_TOKEN"))
#
#chat_completion = client.chat.completions.create(
# model="tgi",
# messages=[
# {"role": "system", "content": "You are a helpful assistant."},
# {"role": "user", "content": "What is Deep Learning?"},
# ],
# temperature=0.7,
# top_p=0.95,
# max_tokens=128,
#)از طرف دیگر، ما یک دستیار شخصی سفارشی ایجاد کردهایم که روی همان سیستم کار میکند. ما توصیه می کنیم از دستیار شخصی برای این کارها استفاده کنید، زیرا با قرار دادن همه چیز در یک پنجره رابط کاربری گرافیکی زیبا، بسیاری از پیچیدگی های تعامل مستقیم با مدل را انتزاعی می کند. برای کسب اطلاعات بیشتر در مورد استفاده از اسکریپت دستیار شخصی، لطفاً این آموزش را بررسی کنید.
نتیجه
در نتیجه، R1 یک گام به جلو برای جامعه توسعه LLM است. فرآیند آنها وعده می دهد که میلیون ها دلار در هزینه های آموزشی صرفه جویی می کند و در عین حال عملکردی قابل مقایسه یا حتی بهتر از مدل های منبع بسته پیشرفته ارائه می دهد. ما DeepSeek را از نزدیک تماشا خواهیم کرد تا ببینیم چگونه آنها همچنان به رشد خود ادامه می دهند زیرا مدل آنها به رسمیت شناخته شده بین المللی می شود.








